Teoria da Resposta ao Item com uso do R
Adilson dos Anjos
Departamento de Estatística - UFPR
Programa de Pós-graduação em Engenharia de Produção, UFSC
aanjos@ufpr.br
Dalton Francisco de Andrade
Departamento de Informática e Estatística, UFSC
dandrade@inf.ufsc.br
15 de março de 2012
Capítulo 1
Introdução
Durante o curso será utilizada a versão mais nova do software R. Este material
foi preparado com a seguinte versão do software R:
[1] "R version 2.14.2 (2012-02-29)"
1.1 Instalar e carregar pacotes
1.1.1 Rstudio
Durante o curso sugere-se a utilização do software RStudio como front-end do
software R. Entre na página www.rstudio.org e baixe a versão compatível com
seu sistema operacional.
1.1.2 Recursos do R para Psicometria (packages)
O software R possui milhares de pacotes (packages) disponíveis. Alguns
desses pacotes foram agrupados em função de áreas em comum. Esses
agrupamentos são chamados de Task Views e estão disponíveis no site do
R.
Em http://cran-r.c3sl.ufpr.br/web/views/ há um conjunto de pacotes
organizados na área de Psicometria chamado Psychometrics que pode ser acessado
em http://cran-r.c3sl.ufpr.br/web/views/Psychometrics.html
Para instalar um pacote, utilize a função install.package('nomedopacote')
(com aspas).
Para utilizar o pacote utilize a função library(nomedopacote) (sem
aspas).
1.1.3 Datasets
Em vários pacotes do R existem conjuntos de dados (datasets) disponíveis, que
são utilizados nos exemplos de utilização de funções. Nesse curso, serão
utilizados dados reais e dados disponíveis em alguns dos pacotes da área de
Psicometria.
Para saber quais os datasets instalados em seu computador digite data().
Para utilizar dados de algum pacote, digite data(nomedodataset).
Capítulo 2
Teoria clássica dos testes (TCT)
Nesse capítulo será apresentado como realizar uma análise clássica
utilizando algumas funções do software R. Serão utilizados os pacotes ltm e
CTT.
2.1 Exemplo: LSAT (ltm)
2.1.1 Dados LSAT
Utilizaremos o conjunto de dados LSAT disponível no pacote ltm que pode ser
obtido da seguinte forma:
> library(ltm)
> data(LSAT)
Para mais informações sobre esse conjunto de dados, utilize ?LSAT.
2.1.2 TCT com pacote ltm
Existem várias estatísticas que podem ser utilizadas para examinar um conjunto
de respostas de um teste. Por exemplo, a correlação bisserial e o coeficiente de
alpha de Cronbach.
A função descript() do pacote ltm aplicada aos dados LSAT fornece os
seguintes resultados:
> lsat.desc<-descript(LSAT)
> names(lsat.desc)
[1] "sample" "perc" "items" "pw.ass"
[5] "n.print" "name" "missin" "data"
[9] "bisCorr" "ExBisCorr" "alpha"
Descriptive statistics for the 'LSAT' data-set
Sample:
5 items and 1000 sample units; 0 missing values
Proportions for each level of response:
0 1 logit
Item 1 0.076 0.924 2.4980
Item 2 0.291 0.709 0.8905
Item 3 0.447 0.553 0.2128
Item 4 0.237 0.763 1.1692
Item 5 0.130 0.870 1.9010
Frequencies of total scores:
0 1 2 3 4 5
Freq 3 20 85 237 357 298
Point Biserial correlation with Total Score:
Included Excluded
Item 1 0.3618 0.1128
Item 2 0.5665 0.1531
Item 3 0.6181 0.1727
Item 4 0.5342 0.1444
Item 5 0.4351 0.1215
Cronbach's alpha:
value
All Items 0.2950
Excluding Item 1 0.2754
Excluding Item 2 0.2376
Excluding Item 3 0.2168
Excluding Item 4 0.2459
Excluding Item 5 0.2663
Pairwise Associations:
Item i Item j p.value
1 1 5 0.565
2 1 4 0.208
3 3 5 0.113
4 2 4 0.059
5 1 2 0.028
6 2 5 0.009
7 1 3 0.003
8 4 5 0.002
9 3 4 7e-04
10 2 3 4e-04
Os resultados mostram a correlação ponto bisserial, o coeficiente alfa de
Cronbah e as associações entre itens além da frequência de respostas de cada
item.
Observe que na análise da associação existem alguns resultados que
indicam dependência entre itens.
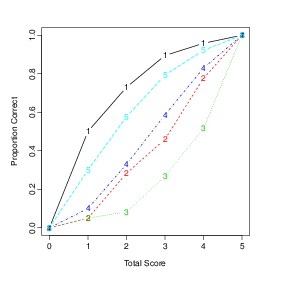
2.1.3 Gráficos
Ainda, é possível fazer um gráfico com os resultados da função descript().
A opção includeFirstLast=TRUE indica que todos os scores devem ser
inseridos no gráfico.
No exemplo observa-se que aqueles que acertaram apenas um item, cerca 50%
destes respondentes acertaram o item 1.
Quando há muitos itens pode ser necessário realizar a análise por
partes:
2.1.4 Correlação bisserial
A correlação bisserial entre o score total e um item pode ser obtida com a
função biserial.cor()
> biserial.cor(rowSums(LSAT), LSAT[[1]])
Compare com a saída da função descript() e observe o sinal da
correlação. O valor é o mesmo mas o sinal é diferente. Isso se deve ao fato de
que a função considerao primeiro nível das respostas para obter o valor da
correlação. Alterando a opção level para 2, obtem-se o mesmo resultado da
função descript():
> biserial.cor(rowSums(LSAT), LSAT[[1]], level = 2)
2.1.5 Coeficiente de Cronbach
A função cronbach.alpha() fornece o valor do coeficiente de correlação de
Cronbah entre os itens.
Cronbach's alpha for the 'LSAT' data-set
Items: 5
Sample units: 1000
alpha: 0.295
Para obter o mesmo resultado da função descript() utilize da seguinte
forma:
> cronbach.alpha(LSAT[-1]) # exclui o item 1
Cronbach's alpha for the 'LSAT[-1]' data-set
Items: 4
Sample units: 1000
alpha: 0.275
2.1.6 TCT com pacote CTT
Além do pacote ltm há também o pacote CTT que pode ser utilizado para
obtenção de algumas estatísticas de interesse na análise clássica de
testes.
Inicialmente carregue o pacote CTT:
A função reliability() do pacote CTT pode ser utilizada para obter o
coeficiente Alpha de Cronbach e outras estatísticas:
> lsat.reliab<-reliability(LSAT)
> names(lsat.reliab)
[1] "N_item" "N_person" "alpha"
[4] "scale.mean" "scale.sd" "alpha.if.deleted"
[7] "pbis" "item.mean"
Number of Items
5
Number of Examinees
1000
Coefficient Alpha
0.295
Por exemplo, pode-se ter interesse na correlação ponto bisserial:
[1] 0.1128327 0.1531781 0.1727789 0.1444281 0.1215964
Observe que essa correlação refere-se ao valor com a exclusão do item, na
ordem em que são apresentados. Compare com os resultados da função
descript().
Para ver mais resultados da função reliability() use:
List of 8
$ N_item : int 5
$ N_person : int 1000
$ alpha : num 0.295
$ scale.mean : num 3.82
$ scale.sd : num 1.04
$ alpha.if.deleted: num [1:5(1d)] 0.275 0.238 0.217 0.246 0.266
$ pbis : num [1:5(1d)] 0.113 0.153 0.173 0.144 0.122
$ item.mean : Named num [1:5] 0.924 0.709 0.553 0.763 0.87
..- attr(*, "names")= chr [1:5] "Item 1" "Item 2" "Item 3" "Item 4" ...
- attr(*, "class")= chr "reliability"
Capítulo 3
Uso do pacote ltm
Nesse capítulo serão utilizadas algumas funções para modelos dicotômicos de
TRI. Em especial, utilizaremos o pacote ltm que é um dos mais completos dentro
do R para uso na TRI.
3.1 Modelos Dicotômicos
Utilizaremos o conjunto de dados LSAT (Law School Admission Test, Bock e
Lieberman (1970)) disponível dentro do pacote ltm:
> library(ltm)
> head(LSAT)
Item 1 Item 2 Item 3 Item 4 Item 5
1 0 0 0 0 0
2 0 0 0 0 0
3 0 0 0 0 0
4 0 0 0 0 1
5 0 0 0 0 1
6 0 0 0 0 1
No capítulo anterior, utilizamos a função descript() para explorar esse
conjunto de respostas:
No resultado da função descript é fornecida a proporção de respostas
para cada item, a frequência de escores, a correlação bisserial e uma
estatística χ2 para associações pareadas entre os cinco items.
rever Segundo Dimitris (2006), associações não significativas podem
indicar itens problemáticos.
3.1.1 Modelo com 3 parâmetros
Para ajustar um modelo com 3 parâmetros utiliza-se a função tpm() da
seguinte maneira.
Os valores dos parâmetros estimados foram:
Call:
tpm(data = LSAT)
Coefficients:
Gussng Dffclt Dscrmn
Item 1 0.037 -3.296 0.829
Item 2 0.078 -1.145 0.760
Item 3 0.012 -0.249 0.902
Item 4 0.035 -1.766 0.701
Item 5 0.053 -2.990 0.666
Log.Lik: -2466.66
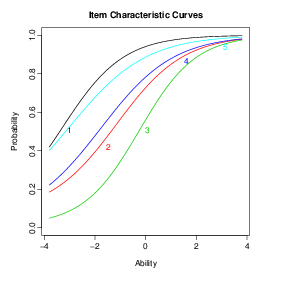
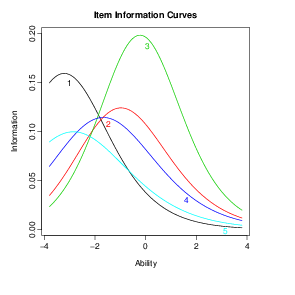
3.1.2 Gráficos
A análise gráfica dos itens também é útil na avaliação do ajuste dos
modelos.
No R a função plot() pode assumir um comportamento específico para
cada tipo de objeto. Por exemplo, a função plot aplicada ao objeto lsat.tpm
produz a CCI.
Uma legenda pode ser incluída com a opção legend=T:
As curvas de informação do item podem ser obtidas da seguinte
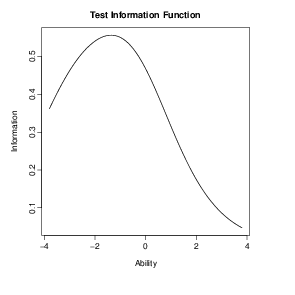
maneira:
A função de informação do teste pode ser obtida da seguinte
maneira:
Um plot do objeto que contém a habilidade fornece um gráfico de densidade
dessa variável.
3.1.3 Estimação da proficiência
Os valores de θ podem ser obtidos com a função factor.scores() aplicada
sobre o objeto da classe tpm que contém as estimativas dos parâmetros do
modelo.
> lsat.prof<-factor.scores(lsat.tpm,method="EAP")
O argumento method permite escolher qual o método de estimação das
proficiências que será utilizado. Veja mais detalhes no arquivo de ajuda da
função (use ?factor.scores).
Os valores de theta estimados são:
Item 1 Item 2 Item 3 Item 4 Item 5 Obs Exp z1
1 0 0 0 0 0 3 2.230 -1.8747570
2 0 0 0 0 1 6 5.820 -1.4504946
3 0 0 0 1 0 2 2.583 -1.4483752
4 0 0 0 1 1 11 8.944 -1.0294589
5 0 0 1 0 0 1 0.701 -1.3994145
6 0 0 1 0 1 1 2.628 -0.9523559
se.z1
1 0.7963477
2 0.7939338
3 0.7910046
4 0.7939350
5 0.8196562
6 0.8208767
3.1.4 Ajuste do modelo com dois parâmetros
O ajuste do modelo com dois parâmetros pode ser obtido com a função
ltm().
Essa função pode ser especificada como uma fórmula onde o lado esquerdo
deve conter objeto com os dados dos respondentes e do lado direito a variável
latente z1:
> fit2<-ltm(LSAT~z1)
> fit2
Call:
ltm(formula = LSAT ~ z1)
Coefficients:
Dffclt Dscrmn
Item 1 -3.360 0.825
Item 2 -1.370 0.723
Item 3 -0.280 0.890
Item 4 -1.866 0.689
Item 5 -3.124 0.657
Log.Lik: -2466.653
3.1.5 Ajuste do modelo de Rasch
A função rasch() do pacote ltm estima o parâmetro de discriminação. Para
definir o parâmetro de discriminação como sendo 1, deve-se utilizar o
argumento constraint.
Esse argumento deve ser fornecido na forma de uma matriz. Assim, para p
itens o número p + 1 indica o parâmetro de discriminação. Assim,
constraint=cbind(length(LSAT)+1,1) indica que o parâmetro p + 1, que
corresponde ao parâmetro de discriminação, deve ser 1.
> fit1<-rasch(LSAT,constraint=cbind(length(LSAT)+1,1))
Observe que o parâmetro de discriminação é 1, igual para todos os
itens.
Para ver o resultado:
Call:
rasch(data = LSAT, constraint = cbind(length(LSAT) + 1, 1))
Model Summary:
log.Lik AIC BIC
-2473.054 4956.108 4980.646
Coefficients:
value std.err z.vals
Dffclt.Item 1 -2.8720 0.1287 -22.3066
Dffclt.Item 2 -1.0630 0.0821 -12.9458
Dffclt.Item 3 -0.2576 0.0766 -3.3635
Dffclt.Item 4 -1.3881 0.0865 -16.0478
Dffclt.Item 5 -2.2188 0.1048 -21.1660
Dscrmn 1.0000 NA NA
Integration:
method: Gauss-Hermite
quadrature points: 21
Optimization:
Convergence: 0
max(|grad|): 6.3e-05
quasi-Newton: BFGS
Uma outra maneira de se obter os valores das estimativas dos parâmetros
é:
> coef(fit1,prob=TRUE, order=TRUE)
Dffclt Dscrmn P(x=1|z=0)
Item 1 -2.8719712 1 0.9464434
Item 5 -2.2187785 1 0.9019232
Item 4 -1.3880588 1 0.8002822
Item 2 -1.0630294 1 0.7432690
Item 3 -0.2576109 1 0.5640489
Sem o argumento constraint, a função estima o parâmetro de
discriminação.
> fit12<-rasch(LSAT)
> summary(fit12)
Call:
rasch(data = LSAT)
Model Summary:
log.Lik AIC BIC
-2466.938 4945.875 4975.322
Coefficients:
value std.err z.vals
Dffclt.Item 1 -3.6153 0.3266 -11.0680
Dffclt.Item 2 -1.3224 0.1422 -9.3009
Dffclt.Item 3 -0.3176 0.0977 -3.2518
Dffclt.Item 4 -1.7301 0.1691 -10.2290
Dffclt.Item 5 -2.7802 0.2510 -11.0743
Dscrmn 0.7551 0.0694 10.8757
Integration:
method: Gauss-Hermite
quadrature points: 21
Optimization:
Convergence: 0
max(|grad|): 2.5e-05
quasi-Newton: BFGS
Os valores de θ podem ser obtidos com a função factor.scores():
> factor.scores(fit2,met="EAP")
Call:
ltm(formula = LSAT ~ z1)
Scoring Method: Expected A Posteriori
Factor-Scores for observed response patterns:
Item 1 Item 2 Item 3 Item 4 Item 5 Obs Exp z1
1 0 0 0 0 0 3 2.277 -1.897
2 0 0 0 0 1 6 5.861 -1.475
3 0 0 0 1 0 2 2.596 -1.455
4 0 0 0 1 1 11 8.942 -1.029
5 0 0 1 0 0 1 0.696 -1.324
6 0 0 1 0 1 1 2.614 -0.897
7 0 0 1 1 0 3 1.179 -0.877
8 0 0 1 1 1 4 5.955 -0.441
9 0 1 0 0 0 1 1.840 -1.432
10 0 1 0 0 1 8 6.431 -1.007
11 0 1 0 1 1 16 13.577 -0.553
12 0 1 1 0 1 3 4.370 -0.418
13 0 1 1 1 0 2 2.000 -0.397
14 0 1 1 1 1 15 13.920 0.054
15 1 0 0 0 0 10 9.480 -1.366
16 1 0 0 0 1 29 34.616 -0.940
17 1 0 0 1 0 14 15.590 -0.919
18 1 0 0 1 1 81 76.562 -0.485
19 1 0 1 0 0 3 4.659 -0.787
20 1 0 1 0 1 28 24.989 -0.349
21 1 0 1 1 0 15 11.463 -0.328
22 1 0 1 1 1 80 83.541 0.125
23 1 1 0 0 0 16 11.254 -0.897
24 1 1 0 0 1 56 56.105 -0.461
25 1 1 0 1 0 21 25.646 -0.441
26 1 1 0 1 1 173 173.310 0.008
27 1 1 1 0 0 11 8.445 -0.304
28 1 1 1 0 1 61 62.520 0.150
29 1 1 1 1 0 28 29.127 0.172
30 1 1 1 1 1 298 296.693 0.646
se.z1
1 0.801
2 0.802
3 0.802
4 0.807
5 0.803
6 0.809
7 0.810
8 0.820
9 0.803
10 0.807
11 0.817
12 0.820
13 0.821
14 0.835
15 0.803
16 0.809
17 0.809
18 0.819
19 0.811
20 0.822
21 0.823
22 0.838
23 0.809
24 0.819
25 0.820
26 0.834
27 0.824
28 0.839
29 0.840
30 0.859
Após a calibração, pode-se utilizar um padrão de respostas qualquer para
estimar a proficiência. Basta fornecer o padrão de repostas da seguinte
forma:
> factor.scores(fit2, resp.patterns = rbind(c(1,0,1,0,1), c(NA,1,0,NA,1)))
Call:
ltm(formula = LSAT ~ z1)
Scoring Method: Empirical Bayes
Factor-Scores for specified response patterns:
Item 1 Item 2 Item 3 Item 4 Item 5 Obs Exp z1
1 1 0 1 0 1 28 24.989 -0.373
2 NA 1 0 NA 1 0 249.424 -0.170
se.z1
1 0.815
2 0.859
Alternativamente, o objeto com o padrão de respostas pode ser fornecido de
outra maneira:
> respostas<-rbind(c(1,0,1,0,1), c(NA,1,0,NA,1))
> respostas
[,1] [,2] [,3] [,4] [,5]
[1,] 1 0 1 0 1
[2,] NA 1 0 NA 1
Aqui o objeto respostas é uma matriz. Observe ainda que existem missings
nas respostas fornecidas.
> factor.scores(fit2, resp.patterns = respostas)
Call:
ltm(formula = LSAT ~ z1)
Scoring Method: Empirical Bayes
Factor-Scores for specified response patterns:
Item 1 Item 2 Item 3 Item 4 Item 5 Obs Exp z1
1 1 0 1 0 1 28 24.989 -0.373
2 NA 1 0 NA 1 0 249.424 -0.170
se.z1
1 0.815
2 0.859
Observe que o erro padrão da estimativas das proficiências é relativamente
alto e que o respondente 2 apesar de não ter apresentado duas respostas,
apresentou uma proficiência maior.
3.2 Questionário sobre Altura (Antigo)
O instrumento de medida apresentado na tabela 3.1 refere-se ao questionário sobre
Altura com 27 itens.
Tabela 3.1: Questionário com item para investigar a altura de pessoas.
| |
|
|
| Item | Descrição (pergunta) |
|
|
| 1 | Ao ficar deitado(a) e esticado(a) em uma cama, meus pés ficam fora do colchão? |
|
|
| 2 | Sou capaz de pegar um objeto no alto de um armário, com meus pés no chão? |
|
|
| 3 | Eu preciso abaixar quando vou passar por uma porta? |
|
|
| 4 | Quando vou dirigir um carro após outra pessoa utilizar, normalmente ajusto o banco para trás? |
|
|
| 5 | Quando vou dirigir um carro após outra pessoa utilizar, normalmente ajusto o banco para frente? |
|
|
| 6 | Tenho dificuldade para me acomodar (ajustar) no banco do ônibus? |
|
|
| 7 | Quando fico de pé no ônibus sinto-me com mais segurança se seguro somente |
| | no pegador superior do ônibus? |
|
|
| 8 | Quando fico de pé no ônibus sinto-me com mais segurança se seguro somente no pegador dos bancos? |
|
|
| 9 | Tenho dificuldade de alcançar a cordinha de solicitação de parada do ônibus? |
|
|
| 10 | Em uma fila, por ordem crescente de tamanho, sou colocado no inicio? |
|
|
| 11 | Quando compro uma calça, geralmente tenho que fazer a bainha? |
|
|
| 12 | Ao sentar corretamente na cadeira, consigo colocar o calcanhar no chão? |
|
|
| 13 | Eu literalmente olho para meus colegas de cima para baixo? |
|
|
| 14 | No supermercado, tenho dificuldades de alcançar ou visualizar produtos na última prateleira? |
|
|
| 15 | Quando ando de bicicleta ajusto a altura do banco para baixo? |
|
|
| 16 | Tenho dificuldade para retirar a bagagem do bagageiro superior do ônibus? |
|
|
| 17 | Quando eu e várias pessoas vamos tirar fotos, formando três colunas, onde ninguém ficará agachado, |
| | costumo ficar na frente? |
|
|
| 18 | Se eu e várias pessoas vamos tirar fotos, formando-se três colunas, onde ninguém ficará agachado, |
| | costumo ficar no meio? |
|
|
| 19 | Em um lugar como uma sala de aula para ver o(a) professor(a) com clareza tenho de sentar-me |
| | na frente das outras pessoas, se não tenho a visão bloqueada por elas? |
|
|
| 20 | Em uma trave de futebol de campo alcanço a trave superior sem pular? |
|
|
| 21 | Em meio a uma multidão consigo avistar pessoas distantes de mim? |
|
|
| 22 | Ao sentar em uma cadeira escolar eu fico desconfortável (incomodado)? |
|
|
| 23 | Ao ficar na soleira da porta eu consigo colocar a palma da mão na batente da porta? |
|
|
| 24 | Consigo alcançar facilmente o chuveiro elétrico para mudar a temperatura? |
|
|
| 25 | Preciso pular para tocar com as pontas dos dedos na batente da porta? |
|
|
| 26 | Em um telefone público, para visualizar o visor digital preciso inclinar a cabeça? |
|
|
| 27 | Eu acho que me daria bem em um time de basquete? |
|
|
| 28 | Qual a sua altura em metros? |
3.2.1 Leitura do arquivo
Os dados podem ser obtidos diretamente do site com os seguinte comandos:
> altura<-read.fwf('http://www.ufpr.br/~aanjos/TRI/dados/altura.dat',widths=c(4,rep(1,27)),
+ header=FALSE,na.strings=9)[-c(1,2),]
A função read.fwf() lê o arquivo considerando as 4 primeiras
colunas como identificadores e cada uma das colunas seguinte como sendo um
item.
V1 V2 V3 V4 V5 V6 V7 V8 V9 V10 V11 V12 V13 V14 V15 V16
3 0001 0 0 0 0 0 0 1 1 1 1 0 1 0 1 1
4 0002 0 1 0 1 1 0 1 1 1 0 1 1 1 1 1
5 0003 1 0 0 0 0 0 0 0 1 1 1 1 0 1 1
6 0004 0 0 0 0 1 0 0 0 1 1 0 1 0 1 1
7 0005 0 1 0 0 0 1 1 1 1 1 0 1 0 1 1
8 0006 0 0 0 0 0 0 0 0 1 0 0 1 0 0 1
V17 V18 V19 V20 V21 V22 V23 V24 V25 V26 V27 V28
3 1 1 1 0 0 0 0 0 0 0 0 0
4 1 1 0 1 1 1 0 1 1 1 0 0
5 1 1 1 1 1 1 0 0 1 1 0 0
6 1 1 1 1 0 NA 1 1 1 1 0 0
7 1 1 1 1 0 1 1 1 1 1 0 1
8 0 0 0 0 0 0 0 0 NA 0 0 1
Os dados necessitam ser formatados para que possam ser analisados no R. A
função colnames() pode ser utilizada para colocar nomes nas colunas
(itens):
> colnames(altura)<-c('id',paste('i',1:27,sep="")) # insere nomes
> head(altura)
id i1 i2 i3 i4 i5 i6 i7 i8 i9 i10 i11 i12 i13 i14 i15
3 0001 0 0 0 0 0 0 1 1 1 1 0 1 0 1 1
4 0002 0 1 0 1 1 0 1 1 1 0 1 1 1 1 1
5 0003 1 0 0 0 0 0 0 0 1 1 1 1 0 1 1
6 0004 0 0 0 0 1 0 0 0 1 1 0 1 0 1 1
7 0005 0 1 0 0 0 1 1 1 1 1 0 1 0 1 1
8 0006 0 0 0 0 0 0 0 0 1 0 0 1 0 0 1
i16 i17 i18 i19 i20 i21 i22 i23 i24 i25 i26 i27
3 1 1 1 0 0 0 0 0 0 0 0 0
4 1 1 0 1 1 1 0 1 1 1 0 0
5 1 1 1 1 1 1 0 0 1 1 0 0
6 1 1 1 1 0 NA 1 1 1 1 0 0
7 1 1 1 1 0 1 1 1 1 1 0 1
8 0 0 0 0 0 0 0 0 NA 0 0 1
Observe que existem respostas ausentes (NA’s).
3.2.2 Ajuste do modelo com dois parâmetros
No R o ajuste de modelos com dois parâmetros pode ser realizado com a
função ltm(). Deve-se redefinir o argumento constraint para que o
parâmetro c seja zero. Nessa opção, no exemplo const=cbind(1:27,1,0),
indica que para os 27 itens (1:27), o parâmetro c (1) será definido como 0
(0).
> altura.tpm<-tpm(altura[,2:28],const=cbind(1:27,1,0))
> altura.tpm
Call:
tpm(data = altura[, 2:28], constraint = cbind(1:27, 1, 0))
Coefficients:
Gussng Dffclt Dscrmn
i1 0 1.403 1.628
i2 0 0.022 2.656
i3 0 3.456 1.626
i4 0 0.303 2.915
i5 0 -0.026 2.377
i6 0 0.827 1.614
i7 0 0.511 1.352
i8 0 -0.164 1.821
i9 0 -1.378 3.518
i10 0 -0.987 1.391
i11 0 0.291 1.615
i12 0 -1.690 1.487
i13 0 1.192 1.462
i14 0 -0.991 3.517
i15 0 -0.969 1.633
i16 0 -1.062 3.694
i17 0 -0.769 3.069
i18 0 -0.243 -0.322
i19 0 -0.778 2.336
i20 0 0.676 1.891
i21 0 0.007 1.672
i22 0 0.450 0.928
i23 0 -0.233 2.375
i24 0 -0.391 2.738
i25 0 -0.596 2.969
i26 0 2.461 0.531
i27 0 1.095 1.551
Log.Lik: -4453.647
Para obter os valores de θ basta aplicar a função factor.scores() sobre o
objeto altura.tpm:
> altura.prof<-factor.scores(altura.tpm)
> head(altura.prof$score)
i1 i2 i3 i4 i5 i6 i7 i8 i9 i10 i11 i12 i13 i14 i15 i16
1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
5 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
6 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
i17 i18 i19 i20 i21 i22 i23 i24 i25 i26 i27 Obs Exp
1 0 0 0 0 0 0 0 0 0 0 0 1 1.956
2 0 0 0 0 0 0 0 0 0 1 0 2 0.169
3 0 0 0 0 0 0 1 0 0 1 0 1 0.003
4 0 0 0 0 0 1 0 0 0 1 0 2 0.017
5 0 0 0 0 1 0 0 0 0 0 0 1 0.064
6 0 1 0 0 0 0 0 0 0 0 0 1 3.725
z1 se.z1
1 -2.038723 0.4423308
2 -1.943124 0.4071593
3 -1.644843 0.3126753
4 -1.807225 0.3606022
5 -1.780174 0.3519735
6 -2.105405 0.4675565
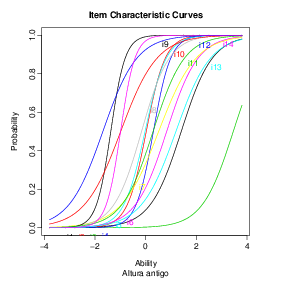
As curvas características dos itens podem ser obtidas da seguinte
maneira:
Outras curvas também podem ser obtidas com os seguintes comandos:
3.2.2.1 Análise pelo pacote irtoys
O modelo com dois parâmetros também pode ser obtido com a função est()
do pacote irtoys. Essa função apresenta mais opções do que a apresentada no
pacote ltm mas utiliza recursos do pacote ltm.
Dentre as opções está a possibilidade de definir a utilização ou não de
prioris para estimação dos parâmetros.
> altura.par<-est(altura[,2:28], model = "2PL", engine = "ltm", nqp = 20, est.distr = FALSE,
+ logistic = TRUE, nch = 5, a.prior = TRUE, b.prior = FALSE, c.prior = FALSE,
+ bilog.defaults = TRUE, rasch = FALSE, run.name = "alturaR")
O objeto altura.par contém os resultados da função est aplicada
sobre os dados de altura. Nesse objeto são armazenados os resultados da
calibração.
[,1] [,2] [,3]
i1 1.5142644 1.3457424 0
i2 2.4924752 -0.1302659 0
i3 1.5684216 3.4542455 0
i4 2.6808932 0.1698579 0
i5 2.2008504 -0.1849514 0
i6 1.5196265 0.7272339 0
i7 1.2968491 0.3847169 0
i8 1.6926909 -0.3311689 0
i9 3.4285136 -1.5996636 0
i10 1.3257223 -1.1939416 0
i11 1.5139391 0.1550446 0
i12 1.4120046 -1.9345432 0
i13 1.4042859 1.0991091 0
i14 3.3658847 -1.2103012 0
i15 1.5575607 -1.1805861 0
i16 3.5472831 -1.2811396 0
i17 2.9670529 -0.9736015 0
i18 -0.3181647 -0.3970970 0
i19 2.2253017 -0.9817770 0
i20 1.7724264 0.5675183 0
i21 1.6110298 -0.1453534 0
i22 0.8659072 0.3264545 0
i23 2.2285484 -0.4065471 0
i24 2.5506268 -0.5760987 0
i25 2.7831521 -0.7965415 0
i26 0.5111392 2.4105038 0
i27 1.4494248 1.0143558 0
Os valores da proficiência (θ) para cada um dos indivíduos pode ser obtido
com a função eap().
> altura.sco<-eap(altura[,2:28],altura.par,qu=normal.qu())
est sem n
[1,] -0.7784428 0.2793523 27
[2,] 0.8096109 0.3445628 27
[3,] -0.1314184 0.2667522 27
[4,] -0.1584988 0.2789522 26
[5,] 0.3410517 0.3121063 27
[6,] -1.4910273 0.2984915 26
3.2.2.2 Obtendo a altura
Por exemplo, pode-se agora, obter a altura de uma pessoa em função das
respostas ao questionário.
Um padrão de respostas poderia ser informado da seguinte maneira:
> resposta<-c(1,1,0,0,0,0,1,0,0,1,1,0,0,0,0,0,1,0,0,1,0,1,1,0,0,0,1)
Estima-se a proficiência de cada pessoa dado o seu padrão de respostas:
> theta.resposta<-eap(resposta, altura.par,qu=normal.qu());theta.resposta
est sem n
[1,] -1.00138 0.2537782 27
Capítulo 4
Equalização
4.1 Equalização
A equalização de testes de diferentes grupos pode ser realizada com a função
plink() do pacote de mesmo nome.
A equalização envolve um arranjo dos itens que permita que a equalização
entre os diferentes grupos seja realizada.
4.1.1 Explicando o exemplo do pacote
Inicialmente carregue o pacote plink:
Nesse exemplo, será utilizado o conjunto de dados disponível no pacote
plink chamado KB04.
Para mais informações sobre esses dados digite ?KB04.
Basicamente esse dataset consiste em dois testes. O grupo X que representa o
novo teste e o grupo Y que representa o teste antigo (referência).
Os testes possuem 36 itens que foram analisados de acordo com um modelo de
3 parâmetros.
Dentro de KB04 são apresentados os itens comuns entre os dois testes.
Para fazer a equalização, é necessário preparar os dados para que sejam
utilizados na função plink().
O objetivo é colocar os parâmetros estimados do teste X na escala
do teste Y.
A função as.poly.mod cria um objeto com o número de itens para serem
analisados. Por default é criado um objeto para itens dicotômicos.
> pm <- as.poly.mod(36)
> pm
An object of class "poly.mod"
Slot "model":
[1] "drm"
Slot "items":
$drm
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
[19] 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
O objeto x será criado para inserir os parâmetros dos itens já estimados
para cada teste.
O argumento cat=list(rep(2,36),rep(2,36)) especifica que o grupo 2 será
o grupo de referência.
O arqumento poly.mod=list(pm,pm) define o modelo e o número de itens em
cada teste.
O argumento exclude=list(27,NA) exclui o item 27 da lista de itens
comuns.
> x <- as.irt.pars(KB04$pars, KB04$common, cat=list(rep(2,36),rep(2,36)),
+ poly.mod=list(pm,pm), exclude=list(27,NA))
Agora, o objeto x contém a configuração necessária para a realização da
equalização.
-------- group1 --------
Total Number of Items: 36
Number of Dichotomous Items: 36
Dichotomous Model: 3PL
Number of Polytomous Items: 0
-------- group2 --------
Total Number of Items: 36
Number of Dichotomous Items: 36
Dichotomous Model: 3PL
Number of Polytomous Items: 0
A função plink() aplicado sobre o objteo x permite realizar a equalização
dos dois testes utilizando vários procedimentos.
Nesse exemplo, utilizou-se o método Mean/Sigma para a equalização.
> out <- plink(x, rescale="MS", base.grp=2, D=1.7)
> out
$link
An object of class "link"
Slot "constants":
$MM
A B
1.217266 -0.557155
$MS
A B
1.168892 -0.515543
$HB
A B
1.092919 -0.457488
$SL
A B
1.101547 -0.476496
Slot "descriptives":
$drm
a b c
N Pars: 12.000000 12.000000 12.000000
Mean: To 0.793383 0.489967 0.151050
Mean: From 0.965758 0.860225 0.159475
SD: To 0.283717 1.245828 0.073638
SD: From 0.446430 1.065820 0.070702
$all
a b c
N Pars: 12.000000 12.000000 12.000000
Mean: To 0.793383 0.489967 0.151050
Mean: From 0.965758 0.860225 0.159475
SD: To 0.283717 1.245828 0.073638
SD: From 0.446430 1.065820 0.070702
Slot "iterations":
HB SL
12 7
Slot "objective":
HB SL
0.000768951 0.009614059
Slot "convergence":
HB SL
"relative convergence (4)" "relative convergence (4)"
Slot "base.grp":
[1] 2
Slot "n":
Total Dichot Poly
12 12 0
Slot "grp.names":
[1] "group1/group2*"
Slot "mod.lab":
[1] "3PL"
Slot "dilation":
[1] "N/A"
$pars
An object of class "irt.pars"
Slot "pars":
$group1
[,1] [,2] [,3]
[1,] 0.4701889 -2.61487303 0.1751
[2,] 0.6750838 -1.07614360 0.1165
[3,] 0.3893431 -1.34557321 0.2087
[4,] 1.2356146 0.04938250 0.2826
[5,] 0.8332677 -0.71191686 0.2625
[6,] 0.4995329 -1.51693278 0.2038
[7,] 0.7360817 0.01583530 0.3224
[8,] 0.9791324 -0.66761585 0.2209
[9,] 0.6453975 -0.49076249 0.1600
[10,] 0.7845036 0.66959660 0.3648
[11,] 0.8206062 0.32816325 0.2399
[12,] 0.5674605 -0.45639706 0.1240
[13,] 1.0543318 -0.02846570 0.2535
[14,] 0.8976022 0.40577767 0.1569
[15,] 0.9145413 0.60776221 0.2986
[16,] 0.7864713 0.19736423 0.2521
[17,] 0.7643991 0.08386482 0.2273
[18,] 0.8274503 -0.28760906 0.0535
[19,] 0.5613863 -0.05347999 0.1201
[20,] 0.9030774 0.59268351 0.2036
[21,] 0.2976323 2.14579031 0.1489
[22,] 0.7213669 0.72359941 0.2332
[23,] 0.9532104 0.16545348 0.0644
[24,] 1.2472495 0.68151930 0.2453
[25,] 0.4394760 1.09635907 0.1427
[26,] 0.7865568 0.74475635 0.0879
[27,] 1.6093018 1.12815293 0.1992
[28,] 1.2871163 1.24866570 0.1642
[29,] 0.8267659 1.28957692 0.1431
[30,] 0.6005687 2.10289197 0.0853
[31,] 1.0823070 1.67718150 0.2443
[32,] 0.7329163 1.48793789 0.0865
[33,] 1.2045595 1.30278540 0.0789
[34,] 0.4968808 3.54378514 0.1399
[35,] 0.7919466 3.13163382 0.1090
[36,] 1.1115655 2.00797794 0.1075
$group2
[,1] [,2] [,3]
[1,] 0.8704 -1.4507 0.1576
[2,] 0.4628 -0.4070 0.1094
[3,] 0.4416 -1.3349 0.1559
[4,] 0.5448 -0.9017 0.1381
[5,] 0.6200 -1.4865 0.2114
[6,] 0.5730 -1.3210 0.1913
[7,] 1.1752 0.0691 0.2947
[8,] 0.4450 0.2324 0.2723
[9,] 0.5987 -0.7098 0.1177
[10,] 0.8479 -0.4253 0.1445
[11,] 1.0320 -0.8184 0.0936
[12,] 0.6041 -0.3539 0.0818
[13,] 0.8297 -0.0191 0.1283
[14,] 0.7252 -0.3155 0.0854
[15,] 0.9902 0.5320 0.3024
[16,] 0.7749 0.5394 0.2179
[17,] 0.5942 0.8987 0.2299
[18,] 0.8081 -0.1156 0.0648
[19,] 0.9640 -0.1948 0.1633
[20,] 0.7836 0.3506 0.1299
[21,] 0.4140 2.5538 0.2410
[22,] 0.7618 -0.1581 0.1137
[23,] 1.1959 0.5056 0.2397
[24,] 1.3554 0.5811 0.2243
[25,] 1.1869 0.6229 0.2577
[26,] 1.0296 0.3898 0.1856
[27,] 1.0417 0.9392 0.1651
[28,] 1.2055 1.1350 0.2323
[29,] 0.9697 0.6976 0.1070
[30,] 0.6336 1.8960 0.0794
[31,] 1.0822 1.3864 0.1855
[32,] 1.0195 0.9197 0.1027
[33,] 1.1347 1.0790 0.0630
[34,] 1.1948 1.8411 0.0999
[35,] 1.1961 2.0297 0.0832
[36,] 0.9255 2.1337 0.1259
Slot "cat":
$group1
[1] 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
[29] 2 2 2 2 2 2 2 2
$group2
[1] 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
[29] 2 2 2 2 2 2 2 2
Slot "poly.mod":
$group1
An object of class "poly.mod"
Slot "model":
[1] "drm"
Slot "items":
$drm
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
[19] 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
$group2
An object of class "poly.mod"
Slot "model":
[1] "drm"
Slot "items":
$drm
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
[19] 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
Slot "common":
group1 group2
[1,] 3 3
[2,] 6 6
[3,] 9 9
[4,] 12 12
[5,] 15 15
[6,] 18 18
[7,] 21 21
[8,] 24 24
[9,] 27 27
[10,] 30 30
[11,] 33 33
[12,] 36 36
Slot "location":
[1] FALSE FALSE
Slot "groups":
[1] 2
Slot "dimensions":
[1] 1 1
Mais detalhes podem ser obtidos com a função summary().
> summary(out, descrip=TRUE)
------- group1/group2* -------
Linking Constants
A B
Mean/Mean 1.217266 -0.557155
Mean/Sigma 1.168892 -0.515543
Haebara 1.092919 -0.457488
Stocking-Lord 1.101547 -0.476496
Common Item Descriptive Statistics
Model: 3PL
Number of Items: 12
a b c
N Pars: 12.000000 12.000000 12.000000
Mean: To 0.793383 0.489967 0.151050
Mean: From 0.965758 0.860225 0.159475
SD: To 0.283717 1.245828 0.073638
SD: From 0.446430 1.065820 0.070702
Os novos parâmetros (reescaldos) podem ser obtidos da seguinte forma:
> pars.out <- link.pars(out)
> pars.out
$group1
[,1] [,2] [,3]
[1,] 0.4701889 -2.61487303 0.1751
[2,] 0.6750838 -1.07614360 0.1165
[3,] 0.3893431 -1.34557321 0.2087
[4,] 1.2356146 0.04938250 0.2826
[5,] 0.8332677 -0.71191686 0.2625
[6,] 0.4995329 -1.51693278 0.2038
[7,] 0.7360817 0.01583530 0.3224
[8,] 0.9791324 -0.66761585 0.2209
[9,] 0.6453975 -0.49076249 0.1600
[10,] 0.7845036 0.66959660 0.3648
[11,] 0.8206062 0.32816325 0.2399
[12,] 0.5674605 -0.45639706 0.1240
[13,] 1.0543318 -0.02846570 0.2535
[14,] 0.8976022 0.40577767 0.1569
[15,] 0.9145413 0.60776221 0.2986
[16,] 0.7864713 0.19736423 0.2521
[17,] 0.7643991 0.08386482 0.2273
[18,] 0.8274503 -0.28760906 0.0535
[19,] 0.5613863 -0.05347999 0.1201
[20,] 0.9030774 0.59268351 0.2036
[21,] 0.2976323 2.14579031 0.1489
[22,] 0.7213669 0.72359941 0.2332
[23,] 0.9532104 0.16545348 0.0644
[24,] 1.2472495 0.68151930 0.2453
[25,] 0.4394760 1.09635907 0.1427
[26,] 0.7865568 0.74475635 0.0879
[27,] 1.6093018 1.12815293 0.1992
[28,] 1.2871163 1.24866570 0.1642
[29,] 0.8267659 1.28957692 0.1431
[30,] 0.6005687 2.10289197 0.0853
[31,] 1.0823070 1.67718150 0.2443
[32,] 0.7329163 1.48793789 0.0865
[33,] 1.2045595 1.30278540 0.0789
[34,] 0.4968808 3.54378514 0.1399
[35,] 0.7919466 3.13163382 0.1090
[36,] 1.1115655 2.00797794 0.1075
$group2
[,1] [,2] [,3]
[1,] 0.8704 -1.4507 0.1576
[2,] 0.4628 -0.4070 0.1094
[3,] 0.4416 -1.3349 0.1559
[4,] 0.5448 -0.9017 0.1381
[5,] 0.6200 -1.4865 0.2114
[6,] 0.5730 -1.3210 0.1913
[7,] 1.1752 0.0691 0.2947
[8,] 0.4450 0.2324 0.2723
[9,] 0.5987 -0.7098 0.1177
[10,] 0.8479 -0.4253 0.1445
[11,] 1.0320 -0.8184 0.0936
[12,] 0.6041 -0.3539 0.0818
[13,] 0.8297 -0.0191 0.1283
[14,] 0.7252 -0.3155 0.0854
[15,] 0.9902 0.5320 0.3024
[16,] 0.7749 0.5394 0.2179
[17,] 0.5942 0.8987 0.2299
[18,] 0.8081 -0.1156 0.0648
[19,] 0.9640 -0.1948 0.1633
[20,] 0.7836 0.3506 0.1299
[21,] 0.4140 2.5538 0.2410
[22,] 0.7618 -0.1581 0.1137
[23,] 1.1959 0.5056 0.2397
[24,] 1.3554 0.5811 0.2243
[25,] 1.1869 0.6229 0.2577
[26,] 1.0296 0.3898 0.1856
[27,] 1.0417 0.9392 0.1651
[28,] 1.2055 1.1350 0.2323
[29,] 0.9697 0.6976 0.1070
[30,] 0.6336 1.8960 0.0794
[31,] 1.0822 1.3864 0.1855
[32,] 1.0195 0.9197 0.1027
[33,] 1.1347 1.0790 0.0630
[34,] 1.1948 1.8411 0.0999
[35,] 1.1961 2.0297 0.0832
[36,] 0.9255 2.1337 0.1259
Capítulo 5
Simulação de respostas no R
5.1 Simulação de respostas utilizando o pacote irtoys
Primeiro carregue o pacote irtoys no R:
5.1.0.1 Modelo de 3 parâmetros
Em seguida, deve-se definir os valores dos parâmetros e o número de itens.
Considere, por exemplo 45 itens para uma prova.
O parâmetro de discriminação a será simulado a partir de uma
Distribuição Uniforme variando de 0,2 até 3 com a utilização da função
runif(). Para cada simulação, deve-se definir uma semente para que o resultado
da simulação possa ser repetido.
> set.seed(2345) # semente
> a<-runif(45,.2,3) # 18 variando no intervalo 0,2 até 3
O parâmetro de dificuldade b será simulado considerando uma sequência de
18 números equidistantes que vai de -2 até 2 utilizando-se a função
seq().
O parâmetro c pode também, ser baseado em uma distribuição uniforme
ou em valores conhecidos a priori.
> set.seed(321)
> #c<-runif(45,.10,.25) ou
> c<-rep(.25,45)
Os valores simulados podem ser agrupados em um data.frame() da seguinte
maneira:
a b c
[1,] 0.5268817 -2.00000000 0.25
[2,] 0.7460703 -1.90909091 0.25
[3,] 2.1840811 -1.81818182 0.25
[4,] 0.2964729 -1.72727273 0.25
[5,] 1.5303363 -1.63636364 0.25
[6,] 1.0236516 -1.54545455 0.25
[7,] 1.8930629 -1.45454545 0.25
[8,] 2.4077543 -1.36363636 0.25
[9,] 1.3403296 -1.27272727 0.25
[10,] 2.1934367 -1.18181818 0.25
[11,] 0.6460858 -1.09090909 0.25
[12,] 1.1592440 -1.00000000 0.25
[13,] 0.4269729 -0.90909091 0.25
[14,] 0.6198062 -0.81818182 0.25
[15,] 1.3493747 -0.72727273 0.25
[16,] 1.1250785 -0.63636364 0.25
[17,] 1.9192593 -0.54545455 0.25
[18,] 1.4157916 -0.45454545 0.25
[19,] 2.0906209 -0.36363636 0.25
[20,] 0.7286267 -0.27272727 0.25
[21,] 2.9442165 -0.18181818 0.25
[22,] 1.5851195 -0.09090909 0.25
[23,] 2.4922230 0.00000000 0.25
[24,] 1.6097531 0.09090909 0.25
[25,] 1.1813937 0.18181818 0.25
[26,] 0.5926241 0.27272727 0.25
[27,] 2.6995558 0.36363636 0.25
[28,] 1.9058324 0.45454545 0.25
[29,] 1.8190562 0.54545455 0.25
[30,] 2.6080916 0.63636364 0.25
[31,] 0.6709691 0.72727273 0.25
[32,] 1.6447777 0.81818182 0.25
[33,] 2.9040783 0.90909091 0.25
[34,] 1.8625741 1.00000000 0.25
[35,] 0.3790259 1.09090909 0.25
[36,] 2.5376286 1.18181818 0.25
[37,] 1.7859149 1.27272727 0.25
[38,] 2.2143143 1.36363636 0.25
[39,] 0.4648870 1.45454545 0.25
[40,] 1.7959496 1.54545455 0.25
[41,] 2.3558405 1.63636364 0.25
[42,] 1.7034367 1.72727273 0.25
[43,] 1.6578749 1.81818182 0.25
[44,] 2.4340014 1.90909091 0.25
[45,] 1.0647566 2.00000000 0.25
É necessário também simular a proficiência dos indivíduos que
respondem o teste. Por exemplo, pode-se simular a proficiência de 100 pessoas
considerando que essa proficiência tenha uma distribuição simétrica. Nesse
caso, pode-se utiliza a função rnorm() para gerar 100 valores da distribuição
Normal com média 0 e desvio padrão 1.
> set.seed(1236)
> pf<-rnorm(100)
No irtoyso padrão de respostas em função dos parâmetros e da
habilidade pode ser obtido com a função sim(). É necessário fornecer os
valores dos parâmetros dos itens e da proficiência dos indivíduos:
> dados.sim<-sim(ip=pa,x=pf)
Agora, o objeto dados.sim contém as respostas de indivíduos para cada um
dos 45 itens:
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] 1 1 1 0 1 0 1 0 1 1
[2,] 1 1 1 1 1 1 1 1 1 1
[3,] 1 1 1 1 1 0 1 1 0 1
[4,] 1 1 1 1 1 0 1 1 1 1
[5,] 1 1 1 1 1 1 1 1 1 0
[6,] 0 1 1 1 1 1 1 1 0 1
[,11] [,12] [,13] [,14] [,15] [,16] [,17] [,18] [,19]
[1,] 0 0 0 1 0 1 1 0 1
[2,] 0 1 1 1 1 1 0 0 0
[3,] 1 1 1 1 0 1 1 1 1
[4,] 1 1 1 1 1 1 1 1 1
[5,] 1 0 0 1 0 0 0 0 1
[6,] 0 1 1 1 1 1 1 1 1
[,20] [,21] [,22] [,23] [,24] [,25] [,26] [,27] [,28]
[1,] 0 1 1 1 0 0 0 0 1
[2,] 1 0 0 1 1 1 0 0 1
[3,] 1 1 1 1 1 1 0 0 0
[4,] 0 1 1 1 0 1 1 0 1
[5,] 0 1 0 0 1 0 0 0 1
[6,] 0 1 0 1 1 1 0 0 1
[,29] [,30] [,31] [,32] [,33] [,34] [,35] [,36] [,37]
[1,] 0 1 0 1 0 0 1 0 0
[2,] 1 0 1 0 0 1 0 0 0
[3,] 0 0 1 0 0 0 0 1 0
[4,] 1 1 1 1 0 0 0 1 1
[5,] 0 1 0 1 1 0 1 0 0
[6,] 0 1 0 0 1 1 1 0 1
[,38] [,39] [,40] [,41] [,42] [,43] [,44] [,45]
[1,] 1 0 0 1 0 1 0 0
[2,] 1 0 0 0 0 0 1 0
[3,] 0 1 0 0 0 0 1 1
[4,] 1 0 1 1 0 1 0 1
[5,] 1 1 0 1 0 1 1 1
[6,] 1 0 0 0 0 0 0 0
Para o padrão de resposta simulado pode-se obter as estimativas dos
parâmetros de um modelo com 3 parâmetros. Inicialmente, considere que o valor
do parâmetro c é conhecido e não será estimado:
> dados.tpm<-tpm(dados.sim,constraint = cbind(1:45, 1, 0.25))
> coef(dados.tpm)
Gussng Dffclt Dscrmn
Item 1 0.25 -3.28798667 0.2302528
Item 2 0.25 -3.78349488 0.3734885
Item 3 0.25 -2.34243980 1.9267562
Item 4 0.25 -0.92571068 0.4536274
Item 5 0.25 -2.95639352 0.9287898
Item 6 0.25 -4.74323848 0.3150632
Item 7 0.25 -2.19298252 1.4451862
Item 8 0.25 -1.73222959 1.7451602
Item 9 0.25 -1.93001622 0.8557002
Item 10 0.25 -1.74960312 1.1508307
Item 11 0.25 -3.41767353 0.2398914
Item 12 0.25 -0.96068699 1.2406259
Item 13 0.25 0.09195059 0.7716867
Item 14 0.25 -0.75905279 0.4743860
Item 15 0.25 -1.25124820 0.6375638
Item 16 0.25 -0.49864753 2.0606970
Item 17 0.25 -0.81917176 2.0854593
Item 18 0.25 -0.73545429 1.9269148
Item 19 0.25 -0.65155378 2.1591340
Item 20 0.25 -0.76858131 0.7102104
Item 21 0.25 -0.55369615 2.1217386
Item 22 0.25 0.03176358 1.9895461
Item 23 0.25 -0.44477299 1.0267255
Item 24 0.25 -0.01583068 1.0268666
Item 25 0.25 -1.44699674 0.3648399
Item 26 0.25 0.47706206 0.2950440
Item 27 0.25 0.34092609 2.8920909
Item 28 0.25 0.42136136 2.0028785
Item 29 0.25 0.38655641 1.3204478
Item 30 0.25 0.37031584 2.4685426
Item 31 0.25 0.45842906 0.3177321
Item 32 0.25 0.91099531 4.2147073
Item 33 0.25 0.78250455 1.8035687
Item 34 0.25 1.20499213 1.4873402
Item 35 0.25 2.88481569 0.1427868
Item 36 0.25 0.96439724 2.2189871
Item 37 0.25 1.16859471 2.8674330
Item 38 0.25 2.63983974 1.0145229
Item 39 0.25 3.06949430 0.5206913
Item 40 0.25 1.41856503 13.5535676
Item 41 0.25 2.00736597 2.7652004
Item 42 0.25 2.45435751 1.0414293
Item 43 0.25 1.67909799 1.1207585
Item 44 0.25 1.43169095 16.3478356
Item 45 0.25 2.40623168 0.7782586
Agora, pode-se sugerir que a função estime os valores de c, sem especificar
constraint.
> dados.tpm<-tpm(dados.sim)
> coef(dados.tpm)
Gussng Dffclt Dscrmn
Item 1 9.052602e-02 -8.7742734733 0.1176229
Item 2 1.729969e-01 -8.4240831822 0.1803861
Item 3 8.999983e-01 -0.4438178090 7.5205927
Item 4 8.004538e-04 -1.6468225866 0.5511815
Item 5 8.285002e-01 -0.4038086295 3.0836119
Item 6 4.648995e-02 -4.4744530119 0.4065744
Item 7 1.781231e-03 -2.2548815119 1.6828047
Item 8 1.162021e-03 -1.8164945165 2.0712340
Item 9 7.852773e-01 0.3624605610 4.4505597
Item 10 4.876221e-01 -0.9626547763 1.7462417
Item 11 1.139315e-01 -7.8625563526 0.1341460
Item 12 4.324137e-04 -1.2590819921 1.3513557
Item 13 5.588192e-01 0.7564826573 23.6236300
Item 14 1.251107e-02 -1.6860562328 0.4931435
Item 15 6.172156e-01 0.4028200022 1.8882868
Item 16 4.165041e-01 -0.1153130177 3.7142935
Item 17 3.820688e-01 -0.4720170632 3.7882500
Item 18 4.861269e-05 -0.9031401375 2.2659264
Item 19 4.639934e-01 -0.0338145877 30.1324362
Item 20 6.381104e-01 0.6546170586 10.0333505
Item 21 4.808539e-01 -0.0312975539 11.2276259
Item 22 4.235198e-01 0.3531125111 3.3411774
Item 23 5.062933e-01 0.3521810951 1.7122403
Item 24 2.623571e-01 0.0004415927 1.4060786
Item 25 1.036108e-02 -2.6539049406 0.3624641
Item 26 1.527668e-02 -1.6614302702 0.2349295
Item 27 1.406344e-01 0.1197226447 3.1265139
Item 28 2.455153e-01 0.3420828288 2.4335911
Item 29 1.405647e-03 -0.2904173219 1.0114117
Item 30 3.838057e-01 0.6495772446 23.9914040
Item 31 1.947493e-02 -1.0512013019 0.3739092
Item 32 2.262465e-01 0.6840847811 16.6283494
Item 33 2.967957e-01 0.6919972501 3.0660505
Item 34 9.575056e-04 0.4496197075 0.9081179
Item 35 2.928483e-01 1.8281901233 0.3069027
Item 36 3.074958e-01 0.7341491514 19.3405915
Item 37 2.280059e-01 0.9501304883 2.7616993
Item 38 2.984605e-01 2.1155337673 2.6669069
Item 39 3.079240e-01 2.0220163956 1.1615101
Item 40 1.593238e-04 0.8575168321 1.2914313
Item 41 2.088056e-01 1.5622466448 2.6318643
Item 42 9.168379e-04 1.3989259351 0.5650123
Item 43 2.827395e-01 1.3503905539 1.7585206
Item 44 2.936567e-01 1.4787752656 6.7905542
Item 45 2.380154e-04 1.1212501013 0.5313858
5.2 Simulação de respostas utilizando o pacote ltm
No pacote ltm existe a função rmvlogis() para simulação de padrões de
resposta dicotômicos para modelos da TRI.
Nesse curso veremos como simular dados considerando respostas dicotômicas
para os modelos de 3 e 2 parâmetros e para o modelo Rasch (1 parâmetro).
A função rmvlogis() pode ser utilizada para simular qualquer um dos
modelos de 1, 2 e 3 parâmetros. O número de parâmetros depende de como é
especificado o argumento theta da função rmvlogis().
O theta pode ser definido de várias maneiras, por exemplo:
-
1.
- modelo de 3 parâmetros:
> theta3<-cbind(.25,seq(-2,2,1),1)
> theta3
[,1] [,2] [,3]
[1,] 0.25 -2 1
[2,] 0.25 -1 1
[3,] 0.25 0 1
[4,] 0.25 1 1
[5,] 0.25 2 1
-
2.
- modelo de 2 parâmetros:
> theta2<-cbind(seq(-2,2,1),runif(5,.8,1.2))
> theta2
[,1] [,2]
[1,] -2 0.8839884
[2,] -1 1.0127848
[3,] 0 0.8370904
[4,] 1 0.8353803
[5,] 2 1.1993749
-
3.
- modelo de 1 parâmetro:
> theta1<-cbind(seq(-2,2,1),1)
> theta1
[,1] [,2]
[1,] -2 1
[2,] -1 1
[3,] 0 1
[4,] 1 1
[5,] 2 1
Para simular dados considerando o modelo de Rasch utilize theta1, para um
modelo com 2 parâmetros utilize theta2 e para um modelo com 3 parâmetros
utilize theta3.
Para um modelo de 3 parâmetros, as respostas de 10 respondentes podem ser
fornecidas da seguinte maneira.
[,1] [,2] [,3] [,4] [,5]
[1,] 1 1 1 1 1
[2,] 1 1 1 1 1
[3,] 1 1 1 1 1
[4,] 1 1 1 1 1
[5,] 1 1 1 1 1
[6,] 1 1 1 1 1
[7,] 1 1 1 1 1
[8,] 1 1 1 1 1
[9,] 1 1 1 1 1
[10,] 1 1 1 1 1
Para um modelo de 2 parâmetros, as respostas de 10 respondentes podem ser
fornecidas da seguinte maneira.
[,1] [,2] [,3] [,4] [,5]
[1,] 1 1 0 0 0
[2,] 1 0 0 0 0
[3,] 1 0 0 0 0
[4,] 1 1 0 0 0
[5,] 1 1 0 0 0
[6,] 1 1 0 0 0
[7,] 1 0 0 0 0
[8,] 1 1 1 0 0
[9,] 1 1 1 1 0
[10,] 1 0 1 0 1
E Para um modelo de 1 parâmetro, as resposta de 10 respondentes podem ser
fornecidas da seguinte maneira.
[,1] [,2] [,3] [,4] [,5]
[1,] 1 1 1 0 0
[2,] 1 1 1 0 1
[3,] 1 0 1 0 0
[4,] 0 1 0 0 0
[5,] 1 0 1 0 0
[6,] 1 1 0 0 0
[7,] 1 1 1 0 0
[8,] 1 1 0 0 0
[9,] 1 1 1 0 0
[10,] 1 0 0 0 0
5.2.1 Uma ilustração de uma simulação
Considere um conjunto de dados simulados com as seguintes características: 37
itens e 600 pessoas.
> # simulação: 37 itens e 600 pessoas
> set.seed(12345)
> a<-runif(37,.2,3)
> b<-seq(-2.5,2.5,length=37)
> set.seed(321)
> c<-rep(.33,37)
> par<-cbind(a,b,c)
> set.seed(1236)
> prof<-rnorm(600)
> dados<-sim(ip=par,x=prof)
> head(dados)
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] 1 1 1 1 1 1 1 1 1 1
[2,] 1 1 1 1 1 1 1 1 1 0
[3,] 1 1 1 1 1 1 1 1 1 1
[4,] 1 1 1 1 1 1 1 1 1 1
[5,] 1 1 0 1 1 1 0 0 1 0
[6,] 1 1 1 1 1 0 1 1 1 1
[,11] [,12] [,13] [,14] [,15] [,16] [,17] [,18] [,19]
[1,] 1 1 0 1 0 1 1 1 0
[2,] 1 1 1 1 0 1 1 1 1
[3,] 1 0 0 0 1 1 1 0 1
[4,] 1 1 1 1 1 0 1 1 1
[5,] 0 0 0 0 1 0 0 1 0
[6,] 1 1 1 0 1 1 1 1 1
[,20] [,21] [,22] [,23] [,24] [,25] [,26] [,27] [,28]
[1,] 0 0 1 0 0 0 1 0 0
[2,] 1 1 1 1 1 1 0 0 1
[3,] 1 0 0 0 1 0 0 1 1
[4,] 1 0 0 1 1 1 1 0 1
[5,] 1 1 1 1 0 1 1 0 0
[6,] 1 1 0 1 1 0 1 1 1
[,29] [,30] [,31] [,32] [,33] [,34] [,35] [,36] [,37]
[1,] 0 0 1 1 1 0 1 1 0
[2,] 1 0 1 0 1 0 1 1 0
[3,] 1 0 0 1 1 0 0 0 1
[4,] 1 1 0 0 0 1 0 0 0
[5,] 1 0 0 1 0 0 0 1 0
[6,] 0 0 1 1 1 1 0 0 1
Considere a estimação dos parâmetros (calibração) do modelo de 3
parâmetros:
> # Calibração
> dados.tpm.orig<-tpm(dados)
> coef(dados.tpm.orig)
Gussng Dffclt Dscrmn
Item 1 9.641313e-11 -3.10434604 2.16567298
Item 2 8.695950e-01 -1.36240309 272.56654706
Item 3 7.695997e-13 -3.63203751 1.40935443
Item 4 8.609015e-22 -2.16550248 3.44254445
Item 5 7.653565e-01 -1.25348063 1.07794192
Item 6 2.675310e-01 -2.09563157 0.66318169
Item 7 3.689610e-01 -1.55394347 1.17661795
Item 8 5.453564e-01 -0.99828788 2.26854925
Item 9 6.294725e-01 -0.81976273 2.54651893
Item 10 2.022050e-01 -1.49093109 2.38185646
Item 11 2.604113e-05 -6.25387460 0.16138347
Item 12 5.975753e-01 0.60013696 1.10089420
Item 13 5.001582e-01 -0.37975957 3.58228938
Item 14 2.159250e-02 -9.31724174 0.07012002
Item 15 4.066378e-22 -1.43999707 1.03208933
Item 16 1.841363e-20 -1.13814235 1.13175115
Item 17 4.849721e-02 -0.93311273 1.15254508
Item 18 4.461038e-01 0.02250488 1.82544277
Item 19 6.560358e-19 -1.48563261 0.54625634
Item 20 3.797071e-01 0.31881971 2.63915084
Item 21 3.178852e-01 0.29950135 1.14310778
Item 22 3.559133e-01 0.59644994 1.74279259
Item 23 2.971388e-01 0.33513149 3.05594541
Item 24 2.131059e-01 0.40573145 1.33598811
Item 25 2.929697e-01 0.90535003 2.24502784
Item 26 2.789134e-01 0.89072747 1.39016184
Item 27 3.375545e-01 1.27671422 2.88367317
Item 28 2.942680e-01 0.81341723 1.63106231
Item 29 3.003283e-01 1.13410591 0.94532039
Item 30 2.526157e-01 1.28013015 1.42103174
Item 31 3.367567e-01 1.79369061 2.91533526
Item 32 5.647896e-01 2.61379908 1.44548165
Item 33 4.682296e-01 2.06676199 37.61403003
Item 34 3.449549e-01 2.04288814 134.03117902
Item 35 2.976267e-01 2.04109179 1.03017467
Item 36 3.883943e-01 2.25831858 30.59389470
Item 37 3.377074e-01 2.10377402 42.12306398
Observe que alguns parâmetros não possuem características razoáveis
para serem utilizados na estimação da proficiência. Por opção, a análise foi
refeita com a exclusão de alguns itens.
> dados.tpm<-tpm(dados[,-c(2,11,12,13,14,33,34,36,37)])
> coef(dados.tpm)
Gussng Dffclt Dscrmn
Item 1 0.0068335682 -3.11998697 2.1396699
Item 2 0.0050822335 -3.62007467 1.4158115
Item 3 0.0010572125 -2.12849496 3.7649423
Item 4 0.7876208652 -1.04330694 1.1748519
Item 5 0.2860247111 -1.99284554 0.6835474
Item 6 0.4920945092 -1.15990726 1.3683953
Item 7 0.5236111599 -1.00938481 2.5092894
Item 8 0.6875769321 -0.61129096 3.2807777
Item 9 0.2114626745 -1.57413749 2.0420604
Item 10 0.0009159927 -1.44631365 1.0269806
Item 11 0.0011522597 -1.15108842 1.1135984
Item 12 0.0084612208 -0.98449274 1.1755740
Item 13 0.4312730615 -0.02475576 1.7656881
Item 14 0.0042831918 -1.46842566 0.5491925
Item 15 0.3899496632 0.34475157 2.7745376
Item 16 0.2756645251 0.15677929 1.0720104
Item 17 0.3276378895 0.51777440 1.5573919
Item 18 0.3478276856 0.45195562 4.4512244
Item 19 0.2261765053 0.43976190 1.3720570
Item 20 0.2841505885 0.91388472 1.9608839
Item 21 0.2970548625 0.92692326 1.5293103
Item 22 0.3301705525 1.25131224 2.6852375
Item 23 0.2795508058 0.80355737 1.4349381
Item 24 0.3085922461 1.16579006 0.9651454
Item 25 0.2888609752 1.31858406 1.8783914
Item 26 0.3358236370 1.78909163 2.8606387
Item 27 0.2957530235 2.57668860 0.1368518
Item 28 0.3125435724 1.89322256 1.2982724
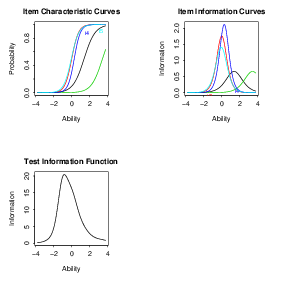
A proficiência pode ser estimada com a função factor.scores():
> theta<-factor.scores(dados.tpm, method = "EAP", prior = TRUE)
> head(theta$score.dat$z1,n=100) # 100 observações/indivíduos
[1] -2.069086447 -1.707089412 -1.636299068 -1.330564487
[5] -1.137091604 -0.938136089 -1.222910118 -1.333087791
[9] 1.116942213 -1.350682627 -0.807981402 -1.151613761
[13] 0.001822315 -2.041948932 -1.333812084 -1.576858719
[17] -1.940895035 -1.552621372 -1.176233643 -2.043702178
[21] -2.252464535 -2.727375995 -2.228160026 -1.193095925
[25] -2.051004042 -2.933389378 -1.437208687 -1.369423914
[29] -0.504287320 -1.354131663 -0.883199792 -1.354969220
[33] 0.666957727 -0.529473495 -0.820160103 -0.683897800
[37] 1.155670986 -1.355184154 -1.159711608 -1.305747181
[41] -1.232743873 -0.877079944 1.132895490 -1.442117803
[45] -1.354171066 -0.703589964 -0.742075267 0.246192176
[49] 0.380220939 -0.907585265 0.656726957 -0.356504322
[53] -0.687653637 -0.578715880 -0.619630749 -0.143577209
[57] 0.110097303 0.091261458 0.870166126 -1.927622962
[61] -0.833587128 -0.988792399 -0.890613300 -0.773356601
[65] -0.747629761 -1.409747094 -1.012955202 -1.246532305
[69] -1.030714192 -1.208568406 -1.313664602 -1.281797129
[73] -1.279362550 -1.089636131 -0.877204074 -0.784307533
[77] -0.870522997 -0.734855914 -1.294391812 -0.680149696
[81] -0.110792782 -0.222933158 -1.325464923 0.191329950
[85] -0.700554862 -0.955063880 -1.074545569 -1.066112763
[89] -1.154586509 -0.799593355 0.730135597 -0.180687107
[93] 1.128615319 0.299407213 0.723461251 -0.072488358
[97] -0.380410845 0.024490558 0.023354257 -0.007764788
Suponha que 3 pessoas responderam o teste, cada uma com uma proficiência
diferente.
> set.seed(1);A<-rbinom(28,1,.6)
> set.seed(2);B<-rbinom(28,1,.87)
> set.seed(3);C<-rbinom(28,1,.9)
> pessoas<-rbind(A,B,C);pessoas
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11]
A 1 1 1 0 1 0 0 0 0 1 1
B 1 1 1 1 0 0 1 1 1 1 1
C 1 1 1 1 1 1 1 1 1 1 1
[,12] [,13] [,14] [,15] [,16] [,17] [,18] [,19] [,20]
A 1 0 1 0 1 0 0 1 0
B 1 1 1 1 1 0 1 1 1
C 1 1 1 1 1 1 1 1 1
[,21] [,22] [,23] [,24] [,25] [,26] [,27] [,28]
A 0 1 0 1 1 1 1 1
B 1 1 1 1 1 1 1 1
C 1 1 1 1 1 1 1 0
Estima-se a proficiência de cada pessoa dado o seu padrão de respostas:
> theta.p<-factor.scores(dados.tpm, method = "EAP", prior = TRUE,resp.patterns=pessoas);theta.p
Call:
tpm(data = dados[, -c(2, 11, 12, 13, 14, 33, 34, 36, 37)])
Scoring Method: Expected A Posteriori
Factor-Scores for specified response patterns:
Item 1 Item 2 Item 3 Item 4 Item 5 Item 6 Item 7 Item 8
A 1 1 1 0 1 0 0 0
B 1 1 1 1 0 0 1 1
C 1 1 1 1 1 1 1 1
Item 9 Item 10 Item 11 Item 12 Item 13 Item 14 Item 15
A 0 1 1 1 0 1 0
B 1 1 1 1 1 1 1
C 1 1 1 1 1 1 1
Item 16 Item 17 Item 18 Item 19 Item 20 Item 21 Item 22
A 1 0 0 1 0 0 1
B 1 0 1 1 1 1 1
C 1 1 1 1 1 1 1
Item 23 Item 24 Item 25 Item 26 Item 27 Item 28 Obs Exp
A 0 1 1 1 1 1 0 0.000
B 1 1 1 1 1 1 0 0.000
C 1 1 1 1 1 0 1 1.629
z1 se.z1
A -1.359 0.190
B 1.369 0.458
C 2.158 0.428
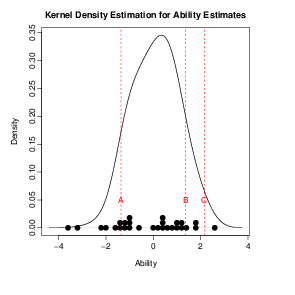
Pode-se, a partir daí, posicionar as pessoas na escala de proficiência obtida
(5.4):