Padronizado pela OMG (Object Management Group) para unificar comunicação entre objetos em linguagens diferentes.

DEE354 - Sistemas Distribuídos

LTSP e Sistemas Multiusuários
LTSP (Linux Terminal Server Project) é um projeto open source que permite a execução de múltiplas sessões de usuários, com processamento centralizado em um único servidor Linux.
Em vez de computadores completos, os usuários utilizam Thin Clients — máquinas simples, com pouco poder de processamento, que apenas exibem a interface gráfica e enviam comandos de entrada (mouse/teclado).
Funcionamento do LTSP
- O servidor LTSP executa todas as aplicações (LibreOffice, navegadores, etc.).
- O cliente leve se conecta via rede (geralmente PXE boot), carrega uma imagem mínima e inicia uma sessão remota no servidor.
- A comunicação ocorre por protocolos como
SSH,X11ouVNC.
Esquema Ilustrativo
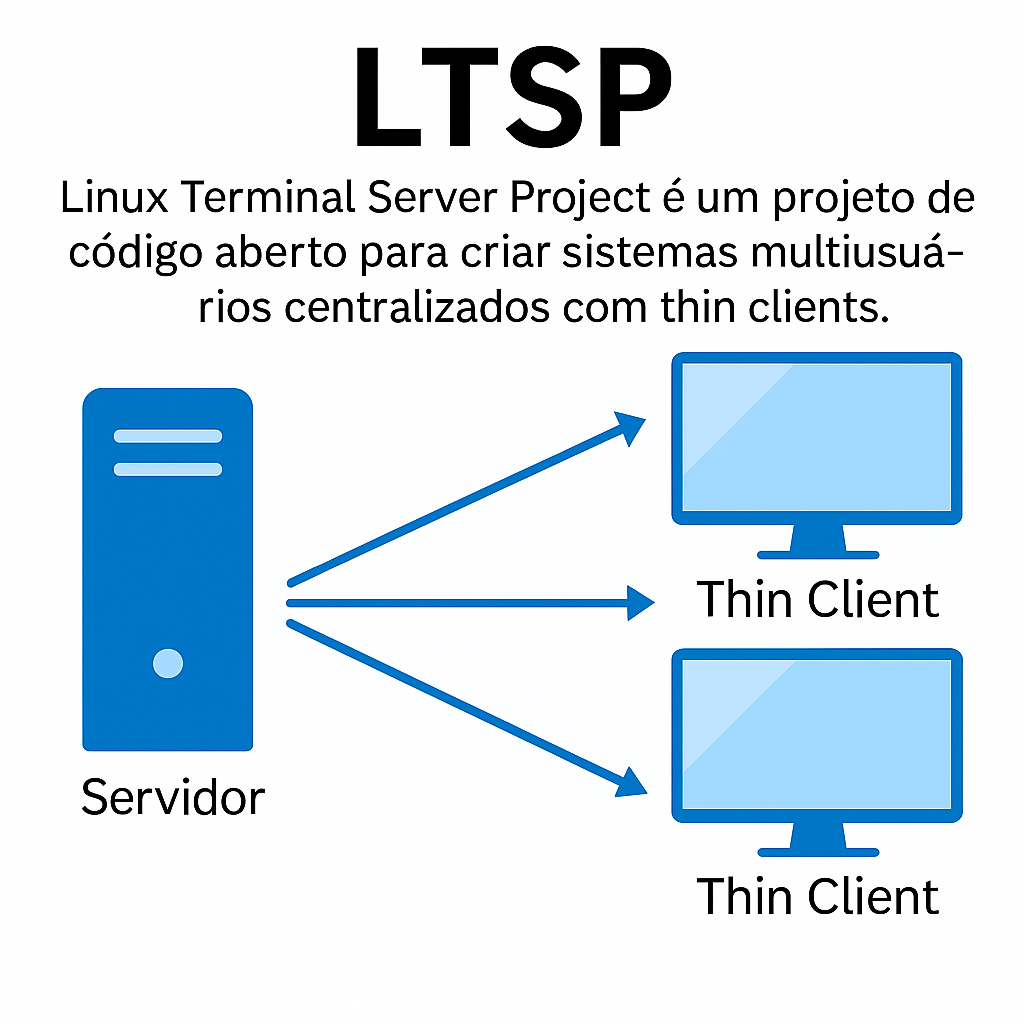
Vantagens do LTSP
- Redução de custos: Thin clients podem ser reaproveitados de máquinas antigas.
- Manutenção centralizada: Apenas o servidor precisa de atualizações e configuração de softwares.
- Segurança: Os dados e aplicações estão centralizados.
- Eficiência energética: Menor consumo em comparação a PCs tradicionais.
Aplicações Reais
- Laboratórios escolares e universitários com orçamento limitado.
- Ambientes corporativos com terminais para atendimento ao cliente (bancos, repartições públicas).
- Telecentros, bibliotecas e centros comunitários.
Comparação com Outros Modelos
- LTSP vs. Virtualização: LTSP oferece sessões independentes para usuários, mas todos os processos rodam diretamente no servidor, sem uma VM por usuário.
- LTSP vs. VDI (Virtual Desktop Infrastructure): VDI geralmente usa máquinas virtuais para cada usuário, o que exige mais recursos.
Sistemas Operacionais Compatíveis
- Distribuições Linux com suporte a LTSP: Ubuntu, Debian, Fedora, openSUSE.
- LTSP moderno (versão 20+): Compatível com Ubuntu 20.04+ e Debian 11+, com suporte a
ltsp-managere imagens baseadas emsystemd-nspawn.
Clusters e HPC: Arquitetura, Aplicações e Futuro
O que é um Cluster?
Definição: Sistema composto por múltiplos computadores (nós) interligados, operando como uma única entidade lógica para:
Desempenho (HPC)
Escalabilidade Horizontal
Tolerância a Falhas
Arquitetura de um Cluster

Head Node (Gerenciador)
Compute Nodes (Tarefas Paralelas)
Storage (Lustre, NFS)
Rede (Infiniband/100Gbps)
- Head Node: Agenda tarefas (SLURM, PBS) e gerencia usuários.
- Compute Nodes: Nós homogêneos ou heterogêneos (CPU/GPU).
- Comunicação: Latência ultrabaixa (Infiniband) ou Ethernet.
Stack Tecnológico
Hardware
x86_64, ARM, GPUs (NVIDIA A100), TPUs, FPGAs
Rede
Infiniband (200Gbps), Ethernet, NVLink (GPU-to-GPU)
Software
Linux (CentOS/Rocky), SLURM, Kubernetes, MPI, OpenMP
Clusters na Prática
2009: Avatar
4.000 nós Linux (Top500) para renderização 3D.
2012: PlayStation 2 Cluster
70 PS2 simulando buracos negros (Universidade de Illinois).
2023: Meta RSC
16.000 GPUs NVIDIA para treino de IA.
O Futuro: Cloud HPC e Edge Clustering
Cloud HPC
AWS Batch, Azure CycleCloud, Google HPC Toolkit.
Edge Clusters
Clusters descentralizados (ex.: carros autônomos).
Grid Computing: Potência Distribuída Globalmente
O que é Grid Computing?
Sistema distribuído que integra recursos computacionais heterogêneos (CPU, GPU, armazenamento) de diferentes domínios administrativos para resolver problemas em larga escala.
🌐
Geograficamente disperso
🧩
Multi-organizacional
⚡
Computação voluntária
Grid vs. Cluster: Principais Diferenças
| Característica | Cluster | Grid |
|---|---|---|
| Localização | Único data center | Global (várias instituições) |
| Gestão | Uma entidade | Múltiplos domínios |
| Hardware | Homogêneo | Heterogêneo (CPU/GPU/ARM) |
| Comunicação | Rede local (Infiniband) | Internet (alta latência) |
| Casos de Uso | HPC, Big Data | Ciência cidadã, projetos globais |
Arquitetura de um Grid

Middleware (Globus Toolkit)
Recursos Distribuídos
Usuário Final
- Middleware: Camada de software que unifica recursos heterogêneos (ex: Globus Toolkit).
- Segurança: Autenticação federada (certificados X.509).
Projetos Famosos de Grid Computing
1999
SETI@Home
Analisou sinais de rádio astronômicos com 5 milhões de voluntários.
2000
Folding@home
Simulação de dobra de proteínas para pesquisa de doenças (ex: COVID-19).
2008
LHC Computing Grid
Processou dados do Large Hadron Collider (CERN) em 170 data centers.
O Futuro do Grid Computing
🖥️ Edge Grids
Integração com dispositivos IoT (ex: carros autônomos compartilhando poder computacional).
🔗 Blockchain + Grid
Incentivos via tokens para participantes (ex: Golem Network).
Computação em Névoa: A Nuvem Desce ao Chão
Padrões e Tecnologias para Sistemas Distribuídos
CORBA: O Middleware Clássico para Objetos Distribuídos
Common Object Request Broker Architecture
1991
"Permitia que um objeto Java chamasse métodos de um objeto C++ remotamente, como se fosse local."
Arquitetura CORBA

IDL (Interface Definition Language)
ORB (Object Request Broker)
IIOP (Protocolo de Rede)
- IDL: Linguagem neutra para definir interfaces (compilável para Java, C++, etc.).
- ORB: "Middleware" que roteia chamadas entre objetos.
- IIOP: Protocolo binário sobre TCP/IP (alternativa ao DCE-RPC).
Exemplo Prático: IDL + Java
// Calculator.idl
module Calculadora {
interface Operacoes {
double soma(in double a, in double b);
double subtrai(in double a, in double b);
};
};
// Servidor Java
public class OperacoesImpl extends OperacoesPOA {
public double soma(double a, double b) {
return a + b;
}
// ... outras implementações
}
O IDL é compilado para stubs (cliente) e skeletons (servidor).
Onde CORBA ainda é Usado?
🏦 Sistemas Bancários Legados
Integração entre mainframes (COBOL) e frontends Java.
🛰️ Sistemas Embarcados Críticos
Comunicação em sistemas de defesa (ex: controle de tráfego aéreo).
CORBA vs. Alternativas Modernas
| CORBA | gRPC | |
|---|---|---|
| Protocolo | IIOP (binário) | HTTP/2 + Protobuf |
| Performance | ~500µs latency | ~100µs latency |
| Complexidade | Alta (IDL, ORB) | Moderada |
Por que CORBA "Morreu"?
- Complexidade: Configurar ORBs era doloroso.
- Alternativas: SOAP (2000s) e gRPC (2010s) ofereciam simplicidade.
- Performance: Protocolos modernos são mais eficientes.
Contribuições
✔ Pioneiro em objetos distribuídos
✔ Padrão multi-linguagem
Lições Aprendidas
✖ Middleware não deve ser invisível
✖ Simplicidade > Features
MPI: Padrão Ouro para HPC Distribuído
Message Passing Interface
1994
Criado por um consórcio de universidades e laboratórios para padronizar a comunicação em clusters HPC.
"Linguagem neutra: funciona com C, C++, Fortran, Python (via mpi4py)."
Arquitetura MPI
👋 Comunicação Ponto-a-Ponto
MPI_Send(buffer, count, datatype, dest, tag, comm); MPI_Recv(buffer, count, datatype, source, tag, comm, status);
📢 Comunicação Coletiva
MPI_Bcast(data, count, datatype, root, comm); MPI_Reduce(sendbuf, recvbuf, count, datatype, op, root, comm);
- Processos: Cada instância do programa tem um rank único (0 a N-1).
- Comunicadores:
MPI_COMM_WORLDagrupa todos os processos. - Latência: Tão baixa quanto 0.5µs com Infiniband.
Exemplo Prático: "Hello World" em MPI
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv) {
MPI_Init(&argc, &argv);
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
printf("Hello from rank %d of %d\n", rank, size);
MPI_Finalize();
return 0;
}
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
print(f"Hello from rank {rank} of {size}")
Compilação (C): mpicc hello.c -o hello && mpirun -np 4 ./hello
Onde MPI Brilha?

Supercomputadores
Fugaku (Japão): 7.3M núcleos usando MPI+OpenMP.
Modelagem Climática
CESM (EUA): Simulações com 100+ variáveis em paralelo.
MPI vs. Outras Abordagens
| MPI | OpenMP | gRPC | |
|---|---|---|---|
| Escala | Clusters (1K+ nós) | Multicore (1 nó) | Microsserviços |
| Latência | 0.5µs (Infiniband) | 10ns (memória) | 100µs (rede) |
| Melhor Caso | Cálculos científicos | Paralelismo fino | Comunicação heterogênea |
Evolução do MPI
- MPI-4.0 (2021): Suporte a fault tolerance e operações persistentes.
- MPI + GPU: Aceleradores (CUDA, ROCm) via
MPI_Senddireto entre GPUs.
OpenMP: Paralelismo em Memória Compartilhada
Open Multi-Processing (OpenMP)
"Framework para paralelismo em memória compartilhada com diretivas simples em C/C++/Fortran."
⚡
Latência: ~10ns (acesso direto à memória RAM)
🧵
Threads: Gerenciadas automaticamente (1 por núcleo)
🔀
Modelo: Fork-Join (threads criadas/destruídas sob demanda)
Arquitetura OpenMP
Thread 1
Núcleo 1
Núcleo 1
Thread 2
Núcleo 2
Núcleo 2
Thread 3
Núcleo 3
Núcleo 3
Thread 4
Núcleo 4
Núcleo 4
- Escopo de Variáveis:
private(cópia por thread) oushared(acesso concorrente). - Diretivas-Chave:
#pragma omp parallel,for,reduction.
Exemplos Práticos
Método de Monte Carlo
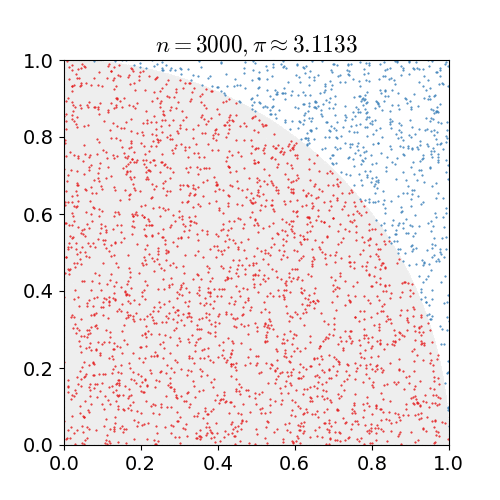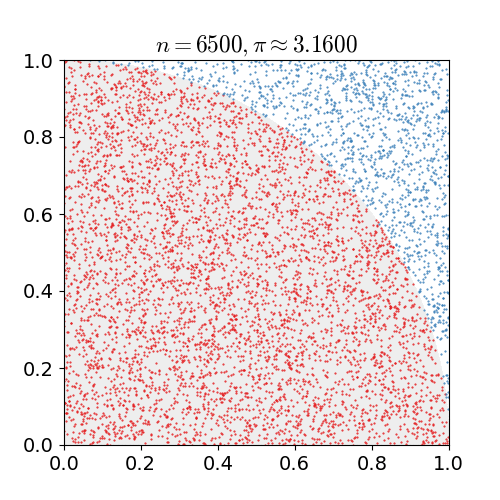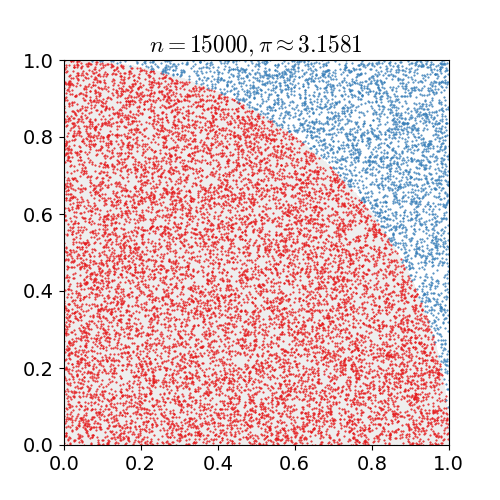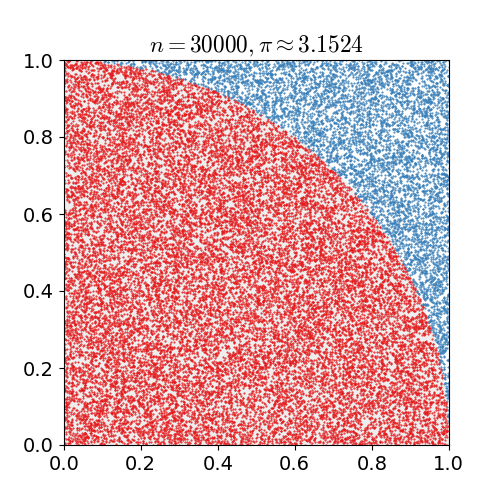
π ≈ 4 × (pontos dentro do círculo / pontos totais). Paralelize a geração de pontos:
#include <stdio.h>
#include <stdlib.h>
int main() {
int points = 1e6;
int inside = 0;
for (int i = 0; i < points; i++) {
double x = (double)rand() / RAND_MAX;
double y = (double)rand() / RAND_MAX;
if (x*x + y*y <= 1) inside++;
}
double pi = 4.0 * inside / points;
printf("π ≈ %f\n", pi);
return 0;
}
#include <omp.h>
// ...
#pragma omp parallel for reduction(+:inside)
for (int i = 0; i < points; i++) {
// Geração de pontos (igual ao serial)
}
printf("π ≈ %f (%d threads)\n", pi, omp_get_max_threads());
Compilação: gcc -fopenmp pi.c -o pi && OMP_NUM_THREADS=4 ./pi
Soma de Elementos de Vetor
Paralelize a soma de um vetor grande usando reduction:
double sum = 0;
for (int i = 0; i < N; i++) {
sum += array[i];
}
double sum = 0;
#pragma omp parallel for reduction(+:sum)
for (int i = 0; i < N; i++) {
sum += array[i];
}
Compilação: gcc -fopenmp sum.c -o sum
Análise de Desempenho
Cálculo de π (1M pontos)
Soma de Vetor (10M elementos)
- Speedup ideal: N threads → N× mais rápido (mas overhead de gerenciamento existe).
- Dica: Use
#pragma omp parallel for schedule(static, chunk)para controlar o balanceamento de carga.
🔄 Casos de Uso
- Processamento de imagens (filtros, convoluções)
- Simulações científicas (equações diferenciais)
- Pré-processamento de dados (ML)
⚠️ Limitações
- Não substitui MPI para clusters (só memória compartilhada)
race conditionsem variáveis compartilhadas semreductionoucritical- Overhead em loops pequenos (< ~1ms)
Exercício: Multiplicação Matriz-Vetor
Paralelize este código com OpenMP:
double result[N];
for (int i = 0; i < N; i++) {
result[i] = 0;
for (int j = 0; j < N; j++) {
result[i] += matrix[i][j] * vector[j];
}
}
Solução
#pragma omp parallel for
for (int i = 0; i < N; i++) {
result[i] = 0;
#pragma omp simd // Otimização adicional
for (int j = 0; j < N; j++) {
result[i] += matrix[i][j] * vector[j];
}
}
Dica: Note o uso de simd para vetorização interna do loop.
gRPC: Chamadas Remotas de Alto Desempenho
O que é gRPC?
"Framework moderno para chamadas remotas (RPC) usando HTTP/2 e Protocol Buffers, desenvolvido pelo Google."
⚡
Latência: ~100µs (5x mais rápido que REST)
📡
Streaming: Suporte a fluxos bidirecionais
🔐
Segurança: TLS nativo e autenticação
Como Funciona?

Cliente
Servidor
HTTP/2
Protocol Buffers
- Protocol Buffers: Estrutura de dados binária (menor que JSON).
- HTTP/2: Multiplexação, compressão de cabeçalhos.
- Stubs Gerados: Código em múltiplas linguagens (Go, Python, Java...).
Exemplo: Serviço de Calculadora
syntax = "proto3";
service Calculator {
rpc Add (AddRequest) returns (AddResponse);
}
message AddRequest {
int32 a = 1;
int32 b = 2;
}
message AddResponse {
int32 result = 1;
}
Compilação: protoc --go_out=. --python_out=. calculator.proto
package main
import (
"context"
"log"
"net"
"google.golang.org/grpc"
pb "caminho/do/proto"
)
type server struct{}
func (s *server) Add(ctx context.Context, req *pb.AddRequest) (*pb.AddResponse, error) {
return &pb.AddResponse{Result: req.A + req.B}, nil
}
func main() {
lis, _ := net.Listen("tcp", ":50051")
s := grpc.NewServer()
pb.RegisterCalculatorServer(s, &server{})
s.Serve(lis)
}
import grpc
import calculator_pb2
import calculator_pb2_grpc
channel = grpc.insecure_channel('localhost:50051')
stub = calculator_pb2_grpc.CalculatorStub(channel)
response = stub.Add(calculator_pb2.AddRequest(a=5, b=3))
print("Resultado:", response.result) # Output: 8
gRPC vs REST
| gRPC | REST/JSON | |
|---|---|---|
| Protocolo | HTTP/2 (binário) | HTTP/1.1 (texto) |
| Payload | Protocol Buffers (compacto) | JSON (verboso) |
| Streaming | ✅ Bidirecional | ❌ Unidirecional |
| Casos de Uso | Microsserviços, IoT | APIs públicas |
Quem Usa gRPC?
Netflix
Comunicação entre microsserviços (1B+ requisições/dia).
Originalmente criado para conectar serviços na nuvem.
Exercício: Implemente um Serviço de Chat
Modifique o exemplo para suportar streaming bidirecional:
service Chat {
rpc SendMessage (stream Message) returns (stream MessageResponse);
}
Solução (Dica)
Use yield no Python e stream.Send() no Go para enviar mensagens assíncronas.
NFS: Sistema de Arquivos Distribuído
Network File System (NFS)
"Protocolo que permite acesso transparente a arquivos remotos como se fossem locais, usando RPC para comunicação."
📅
Origem: Sun Microsystems (1984)
📡
Protocolo: Baseado em RPC (chamadas remotas)
🔗
Versões: NFSv3 (RFC 1813), NFSv4 (RFC 3530)
Como o NFS Funciona?

Cliente
Servidor
RPC/XDR
VFS (Virtual File System)
- VFS: Camada que abstrai operações de arquivo (
open,read, etc.). - XDR: Padroniza representação de dados entre sistemas heterogêneos.
- Stateless: NFSv3 não mantém estado (simplicidade, mas exige cache no cliente).
Configuração em Linux
# Instale o NFS no servidor (Ubuntu) sudo apt install nfs-kernel-server # Configure o diretório exportado sudo mkdir /shared sudo chown nobody:nogroup /shared echo "/shared *(rw,sync,no_subtree_check)" | sudo tee /etc/exports # Inicie o serviço sudo exportfs -a sudo systemctl start nfs-kernel-server
# Instale o cliente NFS sudo apt install nfs-common # Monte o diretório remoto sudo mkdir -p /mnt/nfs/shared sudo mount -t nfs servidor:/shared /mnt/nfs/shared # Verifique df -h | grep nfs ls /mnt/nfs/shared # Arquivos aparecem como locais!
Evolução do Protocolo
| NFSv3 (1995) | NFSv4 (2000) | |
|---|---|---|
| Estado | Stateless | Stateful |
| Segurança | Limitada (Unix auth) | Kerberos, ACLs |
| Performance | UDP (rápido, não confiável) | TCP (confiável) |
| Firewall | Múltiplas portas RPC | Porta única (2049) |
Aplicações no Mundo Real

Clusters HPC
Compartilhamento de datasets grandes entre nós de computação.

Virtualização
Armazenamento centralizado para máquinas virtuais.
Desafios e Alternativas
- ⚠️ Gargalo: Servidor único pode limitar escalabilidade.
- 🔒 Segurança: NFSv3 sem criptografia (use NFSv4 + Kerberos).
- 🔄 Alternativas:
- CephFS: Sistema distribuído com alta disponibilidade.
- Lustre: Para HPC com milhões de arquivos.
Exercício: Monte um Servidor NFS
- Configure um servidor NFSv4 em uma VM Linux.
- Exporte um diretório com
rw(leitura/escrita) para um cliente. - Teste a persistência após reiniciar o servidor.
Dica de Solução
Adicione a montagem automática no /etc/fstab do cliente:
servidor:/shared /mnt/nfs/shared nfs defaults 0 0
Heterogeneidade e Computação Ubíqua
Redes de Sensores e Satélites: IoT e Comunicação Global
Redes de Sensores Sem Fio (WSN)
🔋 Arquitetura Típica

- Nós sensores: Microcontroladores (ex: ESP32) + bateria.
- Gateway: Coleta dados e envia para a nuvem.
- Protocolos: Zigbee, LoRaWAN, Bluetooth Low Energy (BLE).
📊 Casos Reais

Agricultura de Precisão: Sensores monitoram umidade do solo e otimizam irrigação (economia de 30% de água).

Cidades Inteligentes: Sensores em lixeiras acionam coleta quando cheias (ex: Barcelona).
⚙️ Desafios Técnicos
🔋
Energia: Baterias durando anos (ex: LoRaWAN = 10km com AA).
📶
Conectividade: Baixa largura de banda (ex: Zigbee = 250kbps).
🔄
Roteamento: Protocolos como RPL para redes mesh.
🛠️ Exemplo Prático: Sensor ESP32 com LoRa
#include <SPI.h>
#include <LoRa.h>
// Pinos (ajuste para seu hardware)
#define SCK 5 // GPIO5
#define MISO 19 // GPIO19
#define MOSI 27 // GPIO27
#define SS 18 // GPIO18
#define RST 14 // GPIO14
#define DIO0 26 // GPIO26
void setup() {
Serial.begin(115200);
LoRa.setPins(SS, RST, DIO0);
if (!LoRa.begin(915E6)) { // Frequência para Brasil
Serial.println("Falha ao iniciar LoRa!");
while (1);
}
Serial.println("LoRa inicializado!");
}
void loop() {
float temperatura = readTemperature(); // Simulação
float umidade = readHumidity();
// Envia pacote LoRa
LoRa.beginPacket();
LoRa.print("T:");
LoRa.print(temperatura);
LoRa.print("|H:");
LoRa.print(umidade);
LoRa.endPacket();
delay(10000); // Envia a cada 10s
}
void onReceive(int packetSize) {
if (packetSize == 0) return;
String data;
while (LoRa.available()) {
data += (char)LoRa.read();
}
Serial.print("Dados recebidos: ");
Serial.println(data);
// Processa dados (ex: aciona alarme se temperatura > 30°C)
}
void loop() {
LoRa.onReceive(onReceive);
LoRa.receive();
}
Biblioteca: LoRa.h | Plataforma: Arduino IDE/PlatformIO
Redes de Satélites
🛰️ Tipos de Órbitas

- LEO (300-2000km): Starlink, latência ~20ms (para Internet).
- MEO (2000-35,786km): GPS, latência ~100ms.
- GEO (35,786km): Satélites geoestacionários (TV), latência ~500ms.
🌍 Aplicações Críticas
Starlink (SpaceX): 4,000+ satélites LEO para Internet global (velocidade ~300Mbps).

GPS (EUA): 24 satélites MEO para posicionamento (precisão ~3m).
⚡ Desafios de Comunicação
⏱️
Latência: GEO: 500ms ida e volta (vs fibra óptica: ~10ms).
💻
Protocolos: DTN (Delay-Tolerant Networking) para conexões instáveis.
☄️
Ambiente Hostil: Radiação cósmica, lixo espacial.
WSN vs. Satélites: Quando Usar?
| Critério | Redes de Sensores (WSN) | Redes de Satélites |
|---|---|---|
| Custo | 💰 Baixo (nó sensor: $10-$100) | 🚀 Alto (satélite: $500k-$500M) |
| Cobertura | 📶 Local (até 10km com LoRa) | 🌍 Global (incluindo oceanos) |
| Latência | ⚡ Baixa (<100ms) | ⏳ Alta (LEO: 20ms, GEO: 500ms) |
| Manutenção | 🔧 Troca de baterias | 🛰️ Impossível (em órbita) |
| Melhor Caso | 🏭 IoT industrial, agricultura | 🌐 Internet remota, GPS |
Exemplo Integrado: Monitoramento da Amazônia
Sensores no solo: Medem desmatamento (via vibração e som).
➔
Satélites CubeSat: Validam dados e retransmitem.
➔
Nuvem: Aciona alertas em tempo real.
LoRaWAN
DTN
AWS IoT
Exercício: Decida a Tecnologia Ideal
Cenário: Monitorar vulcões ativos em áreas remotas.
- Opção A: Rede de sensores com gateway LoRa via drone.
- Opção B: Nanossatélites CubeSat com sensores térmicos.
Solução
Resposta: Combinação de ambas! Sensores no solo (WSN) para dados precisos + CubeSats para retransmissão em áreas sem infraestrutura.
Por quê? WSN é mais barato para alta densidade de sensores, enquanto satélites garantem cobertura em locais inacessíveis.
Exercício: Simule uma Rede de Sensores
Use o simulador TOSSIM (para TinyOS) ou Cooja (para ContikiOS):
# Exemplo no Cooja (simulando sensores em uma floresta) 1. Crie 10 nós sensores virtuais 2. Implemente roteamento mesh com RPL 3. Monitore consumo de energia
Recursos Adicionais
Arquiteturas Distribuídas
Comunicação em Sistemas Distribuídos
SBRC e Bibliografia
Quiz de Múltipla Escolha
Perguntas Descritivas