
Sincronização em Sistemas Operacionais

Objetivos
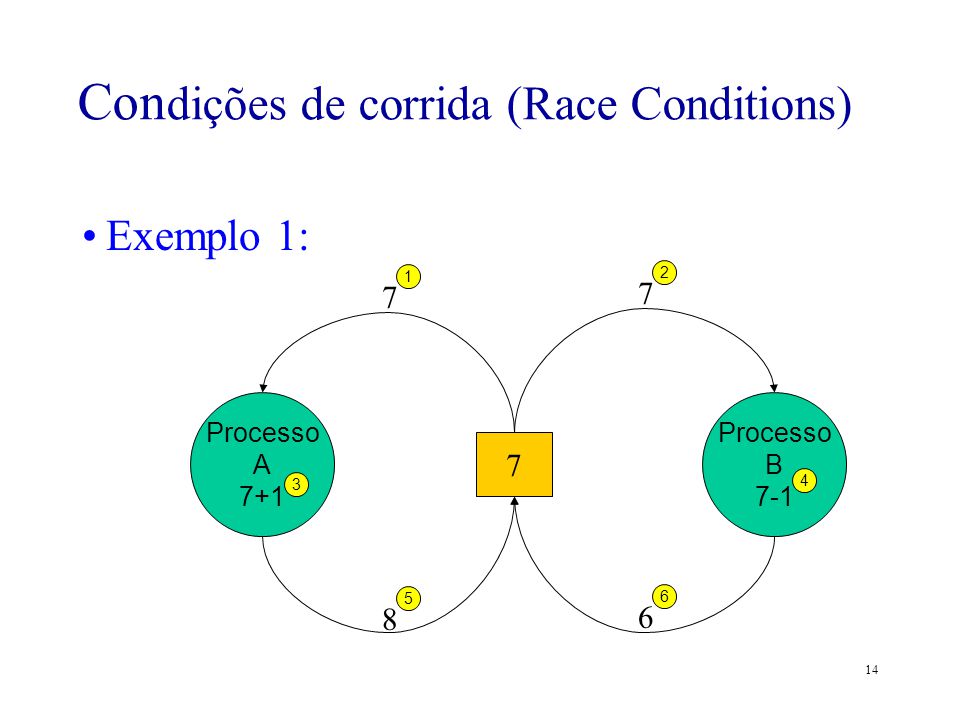
Condição de Corrida
Definição: Ocorre quando dois ou mais processos/threads acessam um recurso compartilhado simultaneamente, sem sincronização, gerando resultados imprevisíveis (Tanenbaum, 2.3.1).
Impacto: Comum em sistemas concorrentes como bancos de dados (ex.: saldo duplicado) ou servidores web (ex.: contagem errada de acessos).
Exemplo Simples:
- Variável compartilhada:
contador = 0 - Processo 1: Lê
contador(0), calcula0 + 1, escreve1 - Processo 2: Lê
contador(0), calcula0 + 1, escreve1 - Resultado final:
contador = 1(esperado:2)
Exemplo em C: Dois threads incrementando uma variável compartilhada contador sem qualquer forma de sincronização (como mutexes).
#include <pthread.h>
#include <stdio.h>
int contador = 0;
void* incrementar(void* arg) {
int temp = contador; // Lê o valor atual
temp = temp + 1; // Incrementa localmente
contador = temp; // Escreve de volta
return NULL;
}
int main() {
pthread_t t1, t2;
pthread_create(&t1, NULL, incrementar, NULL);
pthread_create(&t2, NULL, incrementar, NULL);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
printf("Contador final: %d\\n", contador); // Pode ser 1 ou 2!
return 0;
}
Explicação detalhada:
- Duas threads são criadas:
t1et2. Ambas executam a funçãoincrementar(), que deve incrementar o valor da variável globalcontador. - A função
incrementar()executa três passos:- Lê o valor atual da variável
contadorpara uma variável localtemp. - Incrementa
temp. - Grava o novo valor de
tempde volta emcontador.
- Lê o valor atual da variável
- O problema ocorre porque esses três passos não são atômicos — ou seja, podem ser interrompidos por outra thread no meio da execução.
- Se as duas threads executarem
int temp = contador;quase ao mesmo tempo, ambas podem obter o mesmo valor (ex: 0), incrementá-lo localmente (ficando com 1 emtemp), e então sobrescrevercontadorcom o mesmo valor 1. O resultado final serácontador = 1, mesmo que duas operações de incremento tenham sido feitas.
Resultado esperado: O valor correto de contador após a execução deveria ser 2, mas devido à condição de corrida, ele pode ser 1 ou 2, dependendo da ordem de execução dos threads.
Esse exemplo ilustra:
- A condição de corrida (race condition): quando múltiplas threads acessam e manipulam dados compartilhados ao mesmo tempo e o resultado depende da ordem de execução.
- A necessidade de exclusão mútua (como o uso de mutexes) para proteger seções críticas do código em ambientes concorrentes.
Ponto chave: O erro ocorre porque as instruções de leitura, incremento e escrita podem ser intercaladas (interleaving) entre threads. Mesmo em um único núcleo, o problema ocorre devido à troca de contexto.

Regiões Críticas
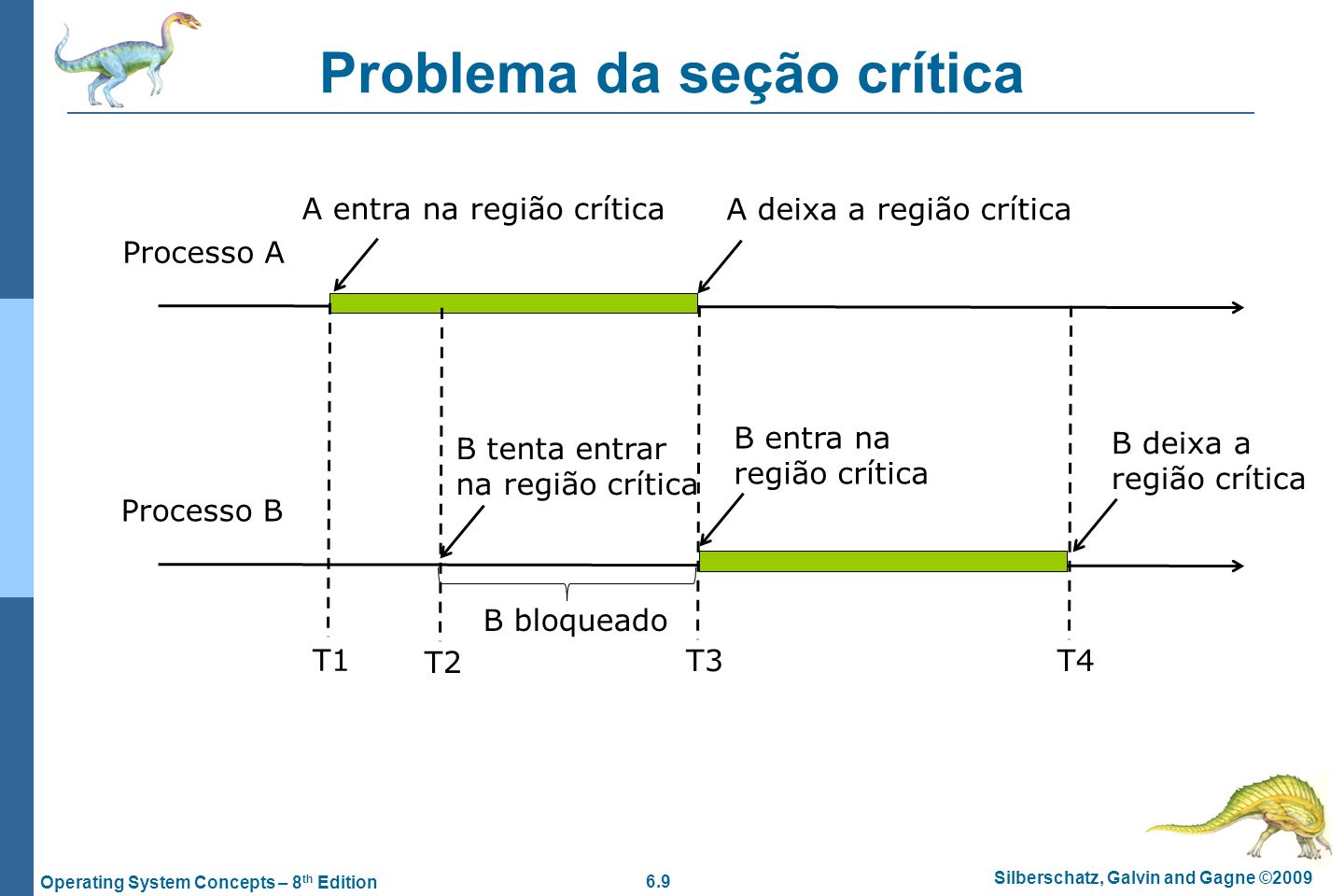
Definição: Seção do código que acessa recursos compartilhados (ex.: variáveis, arquivos) e deve ser executada de forma exclusiva por apenas um processo/thread por vez, evitando condições de corrida (Tanenbaum, 2.3.2).
Importância: Garante consistência em sistemas concorrentes como bancos de dados, servidores e sistemas de arquivos (Maziero, Cap. 8).
Requisitos (Silberschatz, Cap. 5):
- Exclusão Mútua: Apenas um processo na região crítica por vez.
- Progresso: Processos fora da região não podem bloquear os que querem entrar.
- Espera Limitada: Nenhum processo espera indefinidamente para acessar.
Exemplo Prático: Controle de uma fila de impressão em um servidor.
- Sem controle: Dois processos adicionam jobs simultaneamente, corrompendo a fila.
- Com região crítica: Apenas um processo manipula a fila por vez.
Código em C: Incremento protegido por um lock (uso de pthread_mutex_t para garantir exclusão mútua).
#include <pthread.h>
#include <stdio.h>
int contador = 0;
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
void* incrementar(void* arg) {
pthread_mutex_lock(&lock); // Início da região crítica
contador++; // Acesso ao recurso compartilhado
printf("Contador: %d\\n", contador);
pthread_mutex_unlock(&lock); // Fim da região crítica
return NULL;
}
int main() {
pthread_t t1, t2;
pthread_create(&t1, NULL, incrementar, NULL);
pthread_create(&t2, NULL, incrementar, NULL);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
return 0;
}
Explicação detalhada:
- Esse código é similar ao exemplo anterior, mas agora utiliza um
mutexpara proteger a variávelcontadorcontra acessos simultâneos de múltiplas threads. - Antes de acessar o recurso compartilhado, a thread executa
pthread_mutex_lock(&lock);, que garante que apenas uma thread por vez poderá entrar na região crítica. - Dentro da região crítica, a variável
contadoré incrementada com segurança e seu valor é exibido. - Após a operação, a thread libera o bloqueio com
pthread_mutex_unlock(&lock);, permitindo que outra thread possa entrar na região crítica.
Comportamento esperado:
- Ao executar o programa, ambas as threads conseguem incrementar
contadorcom segurança, e o valor final será sempre2. - Isso acontece porque não há mais condição de corrida: o acesso à variável foi serializado via mutex.
Conceitos ilustrados:
- Região crítica: Parte do código que acessa recursos compartilhados e deve ser executada por apenas uma thread por vez.
- Mutex (Mutual Exclusion): Um mecanismo de sincronização usado para proteger regiões críticas em ambientes com múltiplas threads.
- Sincronização: Coordenação do acesso a recursos compartilhados para evitar conflitos ou resultados inconsistentes.
Resultado: Executar várias vezes sempre imprime dois valores e garante que contador = 2, validando o uso correto do mutex.
Exclusão Mútua
Definição: Garante que apenas um processo ou thread acesse uma região crítica por vez, evitando condições de corrida (Tanenbaum, 2.3.3).
Técnica 1 – Espera Ocupada (Busy Waiting): Um processo verifica continuamente (em um laço) o estado de uma variável de controle para saber se pode entrar na região crítica.
#include <stdio.h>
volatile int lock = 0; // Variável de controle compartilhada
void entrar_regiao_critica(int id) {
while (lock == 1); // Espera ocupada: o processo fica preso aqui enquanto o lock estiver ativo
lock = 1; // Entra na região crítica e "tranca" o acesso para os outros
printf("Processo %d na região crítica\\n", id);
lock = 0; // Libera o lock após sair da região crítica
}
int main() {
entrar_regiao_critica(1);
entrar_regiao_critica(2);
return 0;
}
Explicação detalhada:
- A variável
lockatua como uma *flag* de controle: quando vale0, a região crítica está livre; quando vale1, ela está ocupada. - O modificador
volatileé usado para indicar ao compilador que essa variável pode mudar de forma imprevisível (por exemplo, por outro processo ou thread), evitando otimizações indesejadas. - Quando a função
entrar_regiao_critica()é chamada, ela entra em um laçowhileque fica testando a variávellockaté que ela seja0. Isso é o que chamamos de espera ocupada. - Assim que
lockvale0, o processo o define como1(bloqueando a entrada de outros), executa a região crítica (impressão), e em seguida libera a região crítica definindolock = 0.
Comportamento: Embora os dois processos pareçam acessar a função um após o outro no exemplo, a técnica em si demonstra o princípio da espera ocupada em sistemas com concorrência real (várias threads/processos paralelos).
Vantagens:
- Extremamente simples de implementar.
- Funciona em sistemas embarcados ou ambientes com poucos recursos, onde não há suporte a semáforos ou mutexes.
Desvantagens:
- Consome muito tempo de CPU: enquanto o processo espera, ele continua executando instruções (verificando a variável), o que é ineficiente.
- Não é escalável: em sistemas com múltiplos processos concorrentes, a espera ocupada pode causar gargalos e desperdício de recursos.
- Não garante ordem de acesso: pode haver problemas de justiça (um processo pode ficar esperando indefinidamente).
Resumo: Essa técnica serve como uma introdução aos mecanismos de controle de concorrência, mas na prática, é substituída por mecanismos mais eficientes como semáforos, mutexes e monitores.
Importante: Este exemplo não é seguro em arquiteturas modernas, pois não garante atomicidade nem visibilidade entre múltiplos núcleos. Serve apenas para fins didáticos.
Técnica 2 – Test-and-Set: Utiliza uma instrução atômica (não interrompível) para testar e definir o bloqueio simultaneamente. Essa operação é comumente implementada em hardware para garantir que múltiplos processos não acessem uma região crítica ao mesmo tempo.
function test_and_set(lock) {
old = lock;
lock = 1;
return old;
}
while (test_and_set(lock) == 1); // Espera até lock ser 0
// Região crítica
lock = 0; // Libera
Explicação detalhada:
- A função
test_and_setlê o valor atual da variávellocke, ao mesmo tempo, define seu valor para1. - Ela retorna o valor antigo da variável. Se o valor retornado for
1, significa que a região crítica já estava sendo utilizada por outro processo/thread. - O processo entra em um laço de espera até que
test_and_setretorne0, indicando que a região crítica está livre. - Após acessar a região crítica, o processo libera o bloqueio definindo
lock = 0. - Ainda utiliza espera ocupada, porém garante atomicidade da operação.
- Continua consumindo CPU enquanto espera.
Vantagens:
- Evita a condição de corrida por meio de uma operação atômica única.
- Mais eficiente e segura do que a espera ocupada simples, pois garante acesso exclusivo.
Desvantagens:
- Ainda utiliza espera ocupada, consumindo CPU enquanto aguarda a liberação do bloqueio.
- Não garante justiça (alguns processos podem nunca obter acesso à região crítica).
Alternativa Moderna: Uso de pthread_mutex em C para controle eficiente de concorrência. Essa abordagem é recomendada por ser mais eficiente, segura e suportada por bibliotecas de threads modernas (como POSIX).
#include <pthread.h>
#include <stdio.h>
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
void* regiao_critica(void* arg) {
int id = *(int*)arg;
pthread_mutex_lock(&mutex); // Início da região crítica
printf("Thread %d na região crítica\\n", id);
pthread_mutex_unlock(&mutex); // Liberação do mutex
return NULL;
}
Explicação:
pthread_mutex_lockbloqueia o acesso à região crítica para todas as outras threads.- Somente uma thread pode entrar na região protegida por vez, evitando qualquer condição de corrida.
pthread_mutex_unlocklibera o acesso após o uso, permitindo que outra thread entre.- É uma forma moderna, segura e eficiente de garantir exclusão mútua, como recomendado no capítulo 5 do livro do Silberschatz (Operating System Concepts).
Conclusão: Enquanto test-and-set é uma solução mais próxima do hardware e útil para estudo, o uso de mutex é a prática recomendada em sistemas reais e modernos.
Exemplo de Deadlock entre Dois Processos e Dois Recursos
A figura acima representa uma situação clássica de deadlock, onde dois processos estão bloqueados mutuamente esperando por recursos que nunca serão liberados.
- Processo A possui o Recurso 1 e está aguardando o Recurso 2.
- Processo B possui o Recurso 2 e está aguardando o Recurso 1.
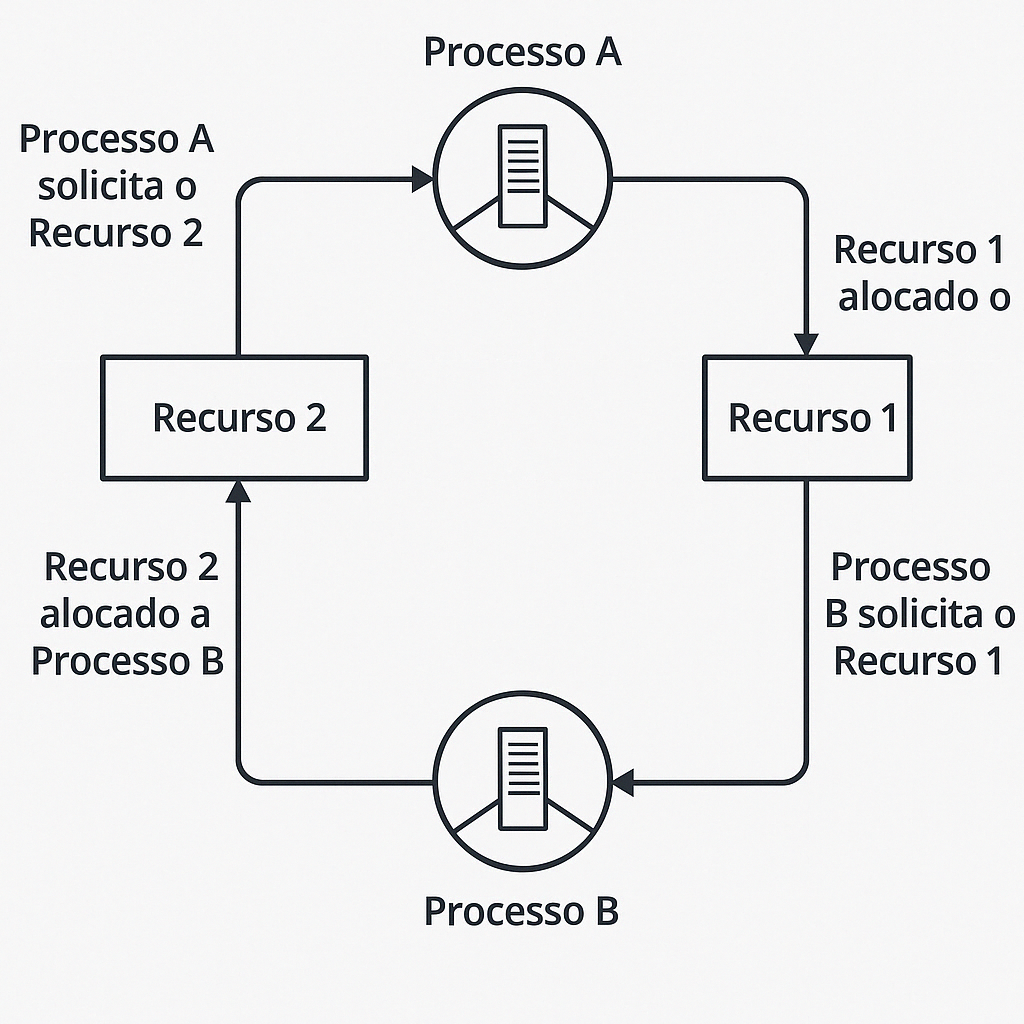
Explicação do Ciclo:
- O Recurso 1 está atualmente alocado ao Processo A.
- O Processo A então solicita o Recurso 2, que está em uso pelo Processo B.
- Simultaneamente, o Recurso 2 está alocado ao Processo B.
- O Processo B solicita o Recurso 1, que está sendo usado pelo Processo A.
Esse ciclo gera um impasse circular, onde:
- Ambos os processos estão em espera bloqueada, esperando por recursos que não serão liberados;
- Nenhum dos dois consegue prosseguir, pois cada um aguarda o recurso que o outro possui;
- Essa situação representa um deadlock, ou seja, uma paralisação indefinida do sistema.
Condições necessárias para o deadlock:
- Exclusão mútua: Os recursos não podem ser compartilhados.
- Posse e espera: Um processo mantém um recurso enquanto espera por outro.
- Não-preempção: O recurso só pode ser liberado voluntariamente pelo processo.
- Espera circular: Há um ciclo de processos, onde cada um espera pelo recurso que o próximo possui.
Na prática: Sistemas operacionais como Linux normalmente não evitam deadlock automaticamente — cabe ao programador evitar essa situação.
Conclusão: Esta representação gráfica ajuda a compreender a origem e o mecanismo do deadlock em sistemas operacionais, sendo essencial para o estudo de estratégias de prevenção e detecção de impasses.
Comparação entre Estratégias de Gerenciamento de Deadlock
| Estratégia | Descrição | Vantagens | Desvantagens |
|---|---|---|---|
| Prevenção | Elimina uma ou mais das condições necessárias para que o deadlock ocorra. | Evita deadlock completamente. | Pode ser ineficiente; reduz paralelismo e flexibilidade do sistema. |
| Evitação | Permite que o sistema entre em estados apenas se forem seguros (ex: algoritmo do banqueiro). | Mais flexível que a prevenção. | Requer conhecimento prévio sobre recursos futuros; difícil de aplicar na prática. |
| Detecção e Recuperação | Permite que o deadlock ocorra, detecta e então toma medidas para corrigir. | Evita restrições desnecessárias durante a execução. | Gera sobrecarga com algoritmos de detecção; recuperação pode ser complexa ou custosa. |
| Ignorar o problema | Assume que deadlocks são raros e não toma medidas específicas (estratégia do "avestruz"). | Simples de implementar; bom desempenho na maioria dos casos. | Se o deadlock ocorrer, o sistema pode travar indefinidamente. |
Observação: A escolha da estratégia depende do tipo de sistema, dos recursos envolvidos e do nível de criticidade da aplicação. Sistemas em tempo real, por exemplo, geralmente não podem ignorar deadlocks.
Algoritmo do Banqueiro
O Algoritmo do Banqueiro, proposto por Dijkstra, é uma técnica de evitação de deadlock que decide se uma solicitação de recurso pode ser atendida com segurança. Ele simula a alocação para verificar se o sistema permanecerá em estado seguro.
O sistema só aceita uma nova alocação se, após essa operação, existe pelo menos uma sequência segura de execução dos processos.
Conceitos-chave:
- Max: Quantidade máxima de recursos que um processo pode solicitar.
- Allocation: Quantidade de recursos que o processo já possui.
- Need:
Need = Max - Allocation. - Available: Recursos disponíveis no sistema.
Passos principais:
- Verifica se
Request ≤ Need. Caso contrário, erro. - Verifica se
Request ≤ Available. Caso contrário, o processo espera. - Executa a alocação "temporária".
- Testa se o sistema está em estado seguro.
- Se sim, mantém a alocação. Se não, desfaz e o processo espera.
Importante: O algoritmo é raramente usado em sistemas reais, pois exige conhecimento prévio das necessidades máximas de recursos.
Diagrama conceitual:
[ Processo P1 ] Max: [7 5 3] Alloc: [0 1 0] Need: [7 4 3] [ Processo P2 ] Max: [3 2 2] Alloc: [2 0 0] Need: [1 2 2] [ Processo P3 ] Max: [9 0 2] Alloc: [3 0 2] Need: [6 0 0] [ Processo P4 ] Max: [2 2 2] Alloc: [2 1 1] Need: [0 1 1] Available: [3 3 2] → Existe uma sequência segura? Exemplo: P2 → P4 → P1 → P3 → ...
Exercício: Simulação do Algoritmo do Banqueiro
Considere os seguintes dados:
| Processo | Max | Allocation | Need |
|---|---|---|---|
| P1 | [7 5 3] | [0 1 0] | [7 4 3] |
| P2 | [3 2 2] | [2 0 0] | [1 2 2] |
| P3 | [9 0 2] | [3 0 2] | [6 0 0] |
| P4 | [2 2 2] | [2 1 1] | [0 1 1] |
Available: [3 3 2]
Questões:
- Existe uma sequência segura de execução? Se sim, qual?
- O processo P2 solicita [1 0 2]. O sistema pode conceder esse pedido?
Dormir e Acordar
Mecanismo: Um processo suspende sua execução (dorme) ao encontrar um recurso indisponível e é despertado (acordado) por outro processo quando o recurso está pronto (Tanenbaum, 2.3.4). Substitui a espera ocupada, economizando CPU.
Funcionamento: Usa sinais (ex.: sleep() e wakeup()) para coordenar processos.
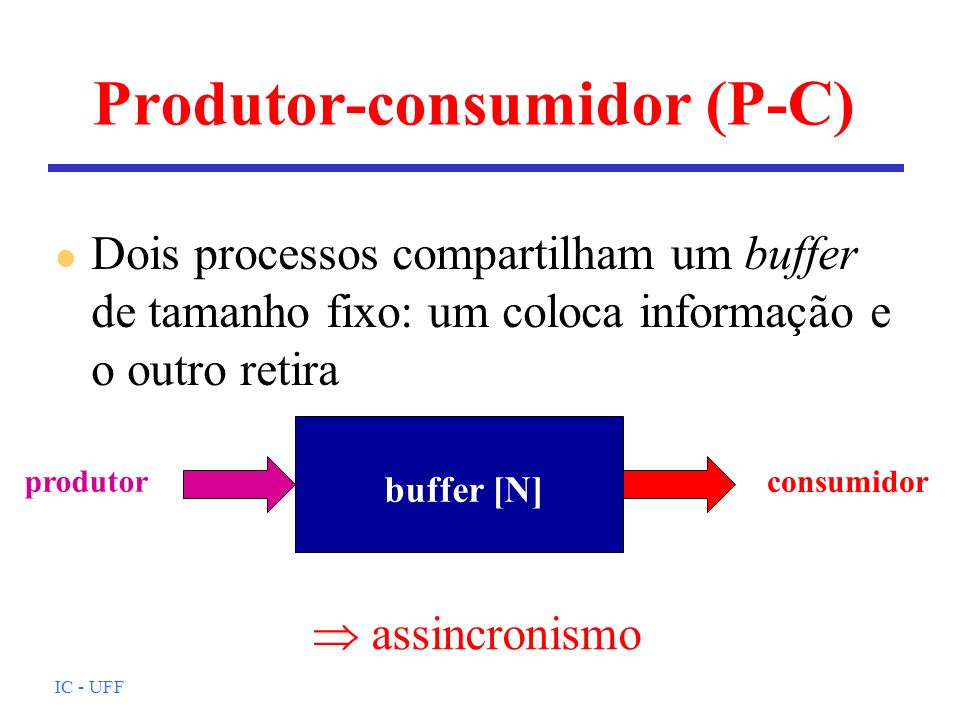
Exemplo – Produtor-Consumidor: O consumidor dorme se o buffer estiver vazio; o produtor o acorda ao adicionar itens.
<#include stdio.h>
<#include pthread.h>
<#include unistd.h>
int itens = 0;
int consumidor_dormindo = 0;
void* produtor(void* arg) {
itens++; // Produz um item
if (consumidor_dormindo) {
printf("Produtor acorda consumidor\\n");
consumidor_dormindo = 0; // Acorda manualmente (simulação)
}
return NULL;
}
void* consumidor(void* arg) {
if (itens == 0) {
printf("Consumidor dorme\\n");
consumidor_dormindo = 1;
sleep(1); // Dorme até ser acordado
}
itens--; // Consome
printf("Consumidor consome: %d\\n", itens);
return NULL;
}
int main() {
pthread_t prod, cons;
pthread_create(&cons, NULL, consumidor, NULL);
sleep(1); // Dá tempo para consumidor dormir
pthread_create(&prod, NULL, produtor, NULL);
pthread_join(cons, NULL);
pthread_join(prod, NULL);
return 0;
}
Observação: Este exemplo é uma simplificação didática. Em sistemas reais, o mecanismo de dormir/acordar é implementado com primitivas do kernel (ex: semáforos, condition variables), não com sleep().
Limitação: Perda de sinais pode ocorrer se o wakeup() for enviado antes do sleep() (Maziero, Cap. 8). Solução: Usar semáforos ou monitores.
Semáforos e Mutexes
Semáforos: Variável de controle para sincronização entre processos/threads (Tanenbaum, 2.3.5).
- Binário: Valores 0 ou 1, usado para exclusão mútua (similar a um lock).
- Contador: Valores ≥ 0, gerencia múltiplos recursos (ex.: vagas em um buffer – Silberschatz, Cap. 5).
- Operações:
P()/down()(decrementa, bloqueia se 0),V()/up()(incrementa, desbloqueia).
Mutexes: Semáforo binário otimizado para exclusão mútua, com posse explícita (Tanenbaum, 2.3.6).
- Característica: Apenas o dono do mutex pode liberá-lo, evitando liberações acidentais.
Cuidado: Uso incorreto de semáforos pode gerar deadlock ou starvation.
Funcionamento de Semáforo Binário – Controle de Acesso à Região Crítica
A imagem representa o ciclo de controle de concorrência utilizando semáforos para garantir a exclusão mútua entre processos que desejam acessar uma região crítica.
- Processo deseja entrar na região crítica:
- O processo tenta executar a operação
DOWN(S)no semáforoS. - Se
S = 1, ele é decrementado paraS = 0e o processo entra na região crítica. - Se
S = 0, o processo é bloqueado e colocado na fila de espera.
- O processo tenta executar a operação
- Processo acessa a região crítica:
- Somente um processo por vez pode estar nessa etapa.
- O valor do semáforo
Spermanece0enquanto a região crítica está ocupada.
- Processo sai da região crítica:
- Executa a operação
UP(S), que defineS = 1e sinaliza que a região crítica está livre. - Se houver processos na fila de espera, o semáforo libera um processo da fila automaticamente para acessar a região crítica.
- Executa a operação
- Fila de espera de processos:
- Contém os processos que tentaram executar
DOWN(S)quandoS = 0. - Esses processos aguardam até que o semáforo seja incrementado por outro processo que saiu da região crítica.
- Contém os processos que tentaram executar
Resumo: O semáforo atua como um mecanismo de bloqueio que controla o acesso à região crítica de forma sincronizada. Ele impede que dois ou mais processos entrem na região crítica simultaneamente, promovendo a exclusão mútua através de operações atômicas DOWN e UP.
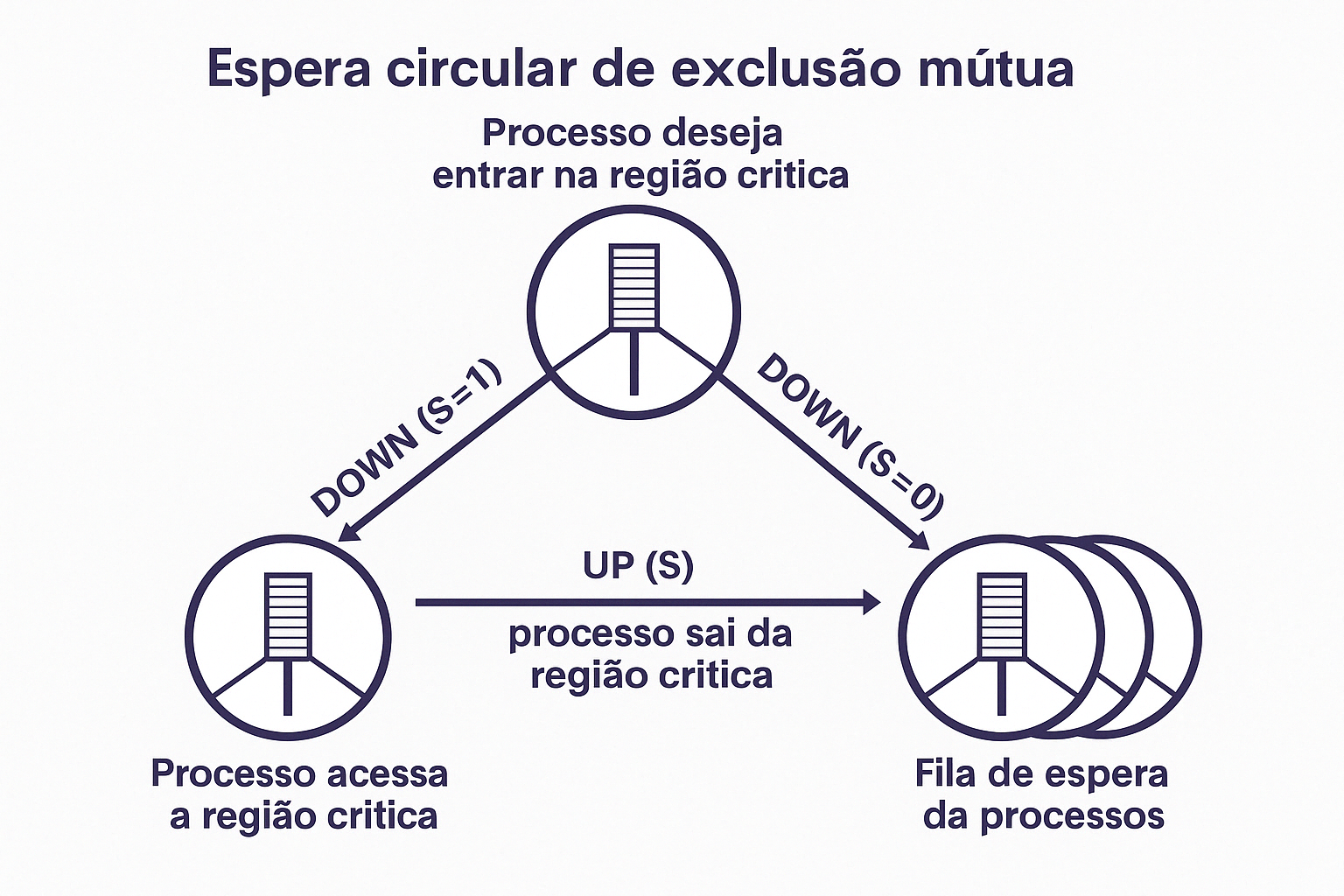
Espera Circular na Exclusão Mútua com Semáforo
A figura acima ilustra o funcionamento de um semáforo binário no controle de acesso à região crítica, utilizando as operações DOWN(S) e UP(S) como mecanismos de dormir e acordar processos.
Explicação do Fluxo:
- Processo deseja entrar na região crítica:
- Executa a operação
DOWN(S). - Se
S == 1, o processo entra na região crítica eSpassa a ser 0. - Se
S == 0, o processo é colocado na fila de espera e entra em estado de dormência.
- Executa a operação
- Processo acessa a região crítica:
- Executa a tarefa que requer exclusão mútua.
- Durante esse período, nenhum outro processo pode entrar.
- Processo sai da região crítica:
- Executa a operação
UP(S), liberando o recurso (S = 1). - Um dos processos na fila de espera é acordado para tentar novamente o
DOWN(S).
- Executa a operação
Conceitos ilustrados:
- Semáforo: Variável usada para controlar acesso a recursos compartilhados. Aqui, está no modo binário (0 ou 1).
- DOWN(S): Decrementa o semáforo. Se
S == 0, o processo dorme. - UP(S): Incrementa o semáforo. Acorda um processo da fila (se houver).
- Fila de espera: Armazena processos bloqueados aguardando o recurso.
Onde usar essa explicação:
Essa figura e explicação se encaixam nas seções de:
- Exclusão Mútua
- Sincronização com Semáforos
- Operações de dormir e acordar processos
- Controle de concorrência com regiões críticas
Resumo: A espera circular representa como processos tentam acessar a região crítica e, se não puderem, entram em uma fila de espera. Ao liberar o recurso com UP(S), um novo processo tem chance de acessar a região protegida, garantindo exclusão mútua.
Figura Semáforo Binário
Exemplo – Produtor-Consumidor com Semáforo e Mutex:
#include <pthread.h>
#include <semaphore.h>
#include <stdio.h>
#define BUFFER_SIZE 2
int buffer[BUFFER_SIZE];
int count = 0;
sem_t sem_vagas, sem_itens; // Semáforos contadores
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
void* produtor(void* arg) {
sem_wait(&sem_vagas); // Espera por uma vaga no buffer
pthread_mutex_lock(&mutex); // Entra na região crítica
buffer[count++] = 1; // Adiciona item ao buffer
printf("Produziu, count: %d\\n", count);
pthread_mutex_unlock(&mutex); // Sai da região crítica
sem_post(&sem_itens); // Sinaliza que há um novo item
return NULL;
}
void* consumidor(void* arg) {
sem_wait(&sem_itens); // Espera por um item disponível
pthread_mutex_lock(&mutex); // Entra na região crítica
count--; // Remove item do buffer
printf("Consumiu, count: %d\\n", count);
pthread_mutex_unlock(&mutex); // Sai da região crítica
sem_post(&sem_vagas); // Sinaliza que uma vaga foi liberada
return NULL;
}
int main() {
sem_init(&sem_vagas, 0, BUFFER_SIZE); // Inicializa semáforo com número de vagas disponíveis
sem_init(&sem_itens, 0, 0); // Inicializa semáforo com 0 itens
pthread_t prod, cons;
pthread_create(&prod, NULL, produtor, NULL);
pthread_create(&cons, NULL, consumidor, NULL);
pthread_join(prod, NULL);
pthread_join(cons, NULL);
sem_destroy(&sem_vagas);
sem_destroy(&sem_itens);
return 0;
}
Explicação detalhada:
- Objetivo: Controlar o acesso concorrente a um buffer limitado, onde um produtor insere dados e um consumidor retira dados.
- Semáforo
sem_vagas: Controla o número de posições livres no buffer. O produtor só pode inserir quando houver vaga. - Semáforo
sem_itens: Controla o número de itens disponíveis no buffer. O consumidor só pode retirar se houver pelo menos um item. - Mutex: Garante que apenas uma thread (produtor ou consumidor) acesse e modifique a variável
countpor vez, evitando condição de corrida. - Quando o produtor é executado:
- Espera por uma vaga com
sem_wait(&sem_vagas). - Tranca o mutex para acessar a região crítica e incrementa o contador.
- Libera o mutex e sinaliza que há um novo item com
sem_post(&sem_itens).
- Espera por uma vaga com
- Quando o consumidor é executado:
- Espera por um item com
sem_wait(&sem_itens). - Tranca o mutex para acessar a região crítica e decrementa o contador.
- Libera o mutex e sinaliza que há uma nova vaga com
sem_post(&sem_vagas).
- Espera por um item com
Funcionamento: O sistema funciona mesmo com múltiplos produtores e consumidores, respeitando os limites do buffer e garantindo exclusão mútua no acesso à variável compartilhada count.
Interpretação importante:
- Semáforos: controlam a quantidade de recursos disponíveis (vagas e itens)
- Mutex: protege o acesso à região crítica (variável
count)
Comparação:
- Semáforo: Permite controlar múltiplos recursos ou slots; ideal para gerenciar disponibilidade (vagas/itens).
- Mutex: Focado na proteção de uma região crítica única; é leve e eficiente quando há apenas uma variável compartilhada.
Resumo: Essa solução híbrida com semáforo + mutex é uma abordagem clássica para resolver problemas de sincronização e coordenação entre threads, garantindo tanto a integridade dos dados quanto o respeito à capacidade do buffer.
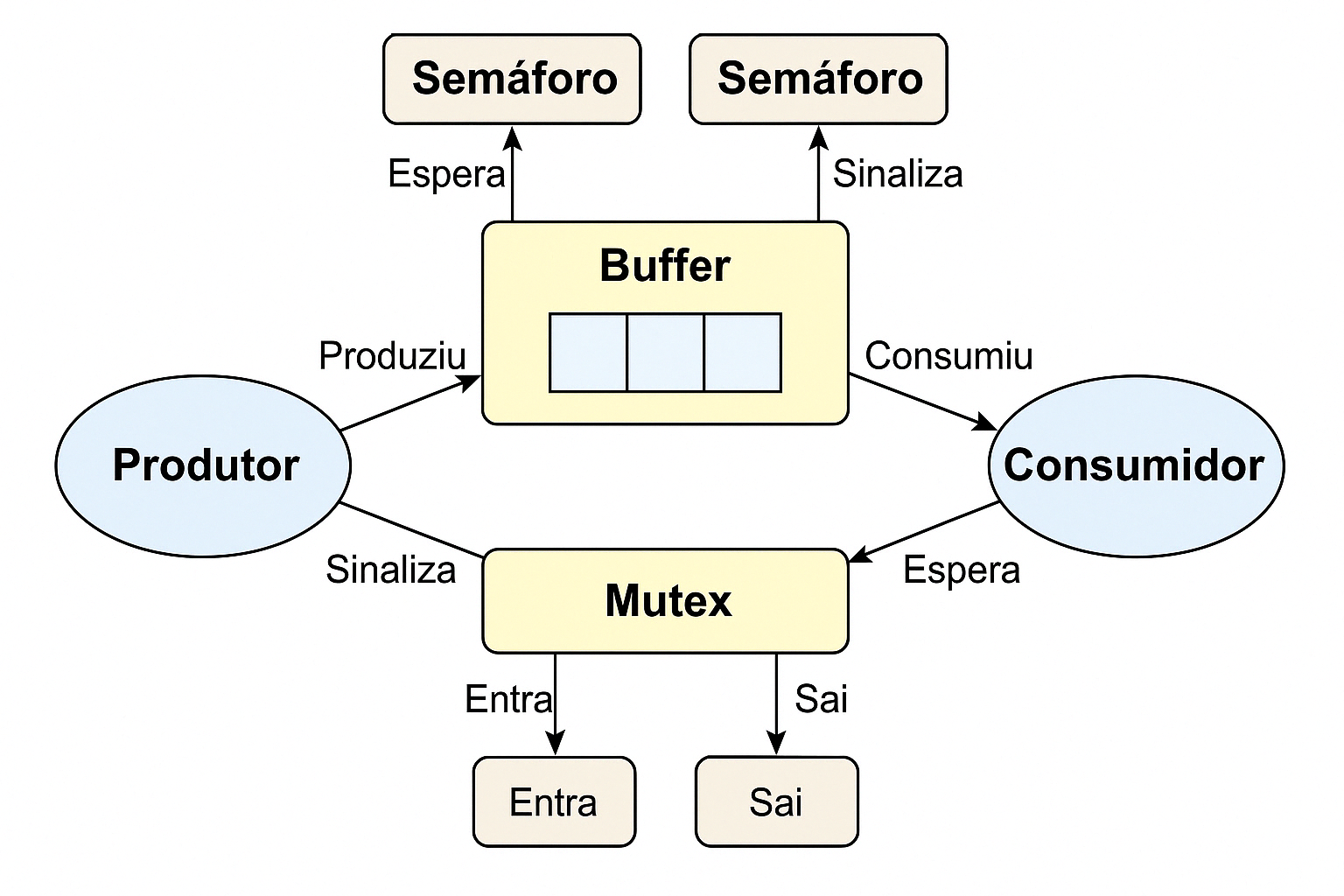
Ilustração – Produtor-Consumidor com Semáforo e Mutex
A figura acima representa visualmente o funcionamento da solução clássica do problema Produtor-Consumidor utilizando semáforos e mutex.
- Produtor: Responsável por gerar itens e colocá-los no buffer. Representado na figura à esquerda, ele:
- Espera por uma vaga disponível no buffer utilizando o semáforo (
sem_wait(&sem_vagas)); - Adquire o mutex para entrar na região crítica e acessar o buffer;
- Produz um item e incrementa o contador;
- Libera o mutex e sinaliza que há um novo item com
sem_post(&sem_itens).
- Espera por uma vaga disponível no buffer utilizando o semáforo (
- Consumidor: Responsável por consumir os itens do buffer. Representado na figura à direita, ele:
- Espera por um item disponível no buffer utilizando o semáforo (
sem_wait(&sem_itens)); - Adquire o mutex para entrar na região crítica e acessar o buffer;
- Consome o item e decrementa o contador;
- Libera o mutex e sinaliza que uma vaga foi liberada com
sem_post(&sem_vagas).
- Espera por um item disponível no buffer utilizando o semáforo (
- Buffer: Local onde os dados produzidos são armazenados temporariamente. Tem tamanho fixo (no exemplo, 2 posições) e é protegido contra acessos simultâneos.
- Semáforos:
- Um controla o número de vagas (
sem_vagas) no buffer; - Outro controla o número de itens disponíveis (
sem_itens); - São utilizados para sincronização entre produtor e consumidor.
- Um controla o número de vagas (
- Mutex: Controla o acesso exclusivo à região crítica (acesso e modificação da variável
count), garantindo que apenas uma thread modifique o buffer por vez.
Elementos da imagem:
- Buffer: Armazena temporariamente os dados produzidos até serem consumidos.
- Semáforo (cima):
sem_vagas: controlado pelo produtor, decrementado antes de produzir, incrementado após o consumidor consumir.sem_itens: controlado pelo consumidor, decrementado antes de consumir, incrementado após o produtor produzir.
- Mutex: Garante que apenas uma thread (produtor ou consumidor) acesse o buffer por vez.
- Setas: Indicam o fluxo de execução e as interações com os semáforos e mutex.
Resumo da dinâmica: O produtor só produz quando há espaço disponível, e o consumidor só consome quando há itens no buffer. Ambos usam o mutex para garantir exclusão mútua no acesso à estrutura compartilhada.
Estudo de Caso: Produtor-Consumidor com Semáforos
Monitores
Definição: Estrutura de alto nível que encapsula dados compartilhados e métodos, garantindo exclusão mútua automática (Tanenbaum, 2.3.7). Usa variáveis de condição (wait() e signal()) para sincronizar processos/threads (Silberschatz, Cap. 5).
Funcionamento: Um monitor combina dados compartilhados (ex.: buffers, contadores) e métodos (ex.: inserir, remover) em uma entidade protegida, permitindo que apenas um processo/thread a acesse por vez, evitando condições de corrida. A exclusão mútua é gerenciada automaticamente, sem necessidade de locks explícitos. Variáveis de condição controlam a sincronização: wait() suspende um processo/thread, liberando o monitor, enquanto signal() desperta um processo/thread em espera, como no problema produtor-consumidor, onde produtores esperam por espaço e consumidores por dados.
Vantagens: Simplifica a programação concorrente com exclusão mútua automática, reduz erros como deadlocks e condições de corrida, e centraliza o controle de acesso aos dados, facilitando a manutenção. As variáveis de condição permitem sincronização precisa, ideal para problemas como produtor-consumidor ou leitores-escritores.
Limitações: Nem todas as linguagens suportam monitores nativamente (ex.: C requer bibliotecas), o que pode complicar a implementação. Menos flexível que semáforos para cenários complexos, e o uso incorreto de wait() e signal() pode causar problemas como starvation, onde um thread nunca é acordado.
Importante: Monitores encapsulam automaticamente a exclusão mútua, evitando erros comuns no uso manual de semáforos.
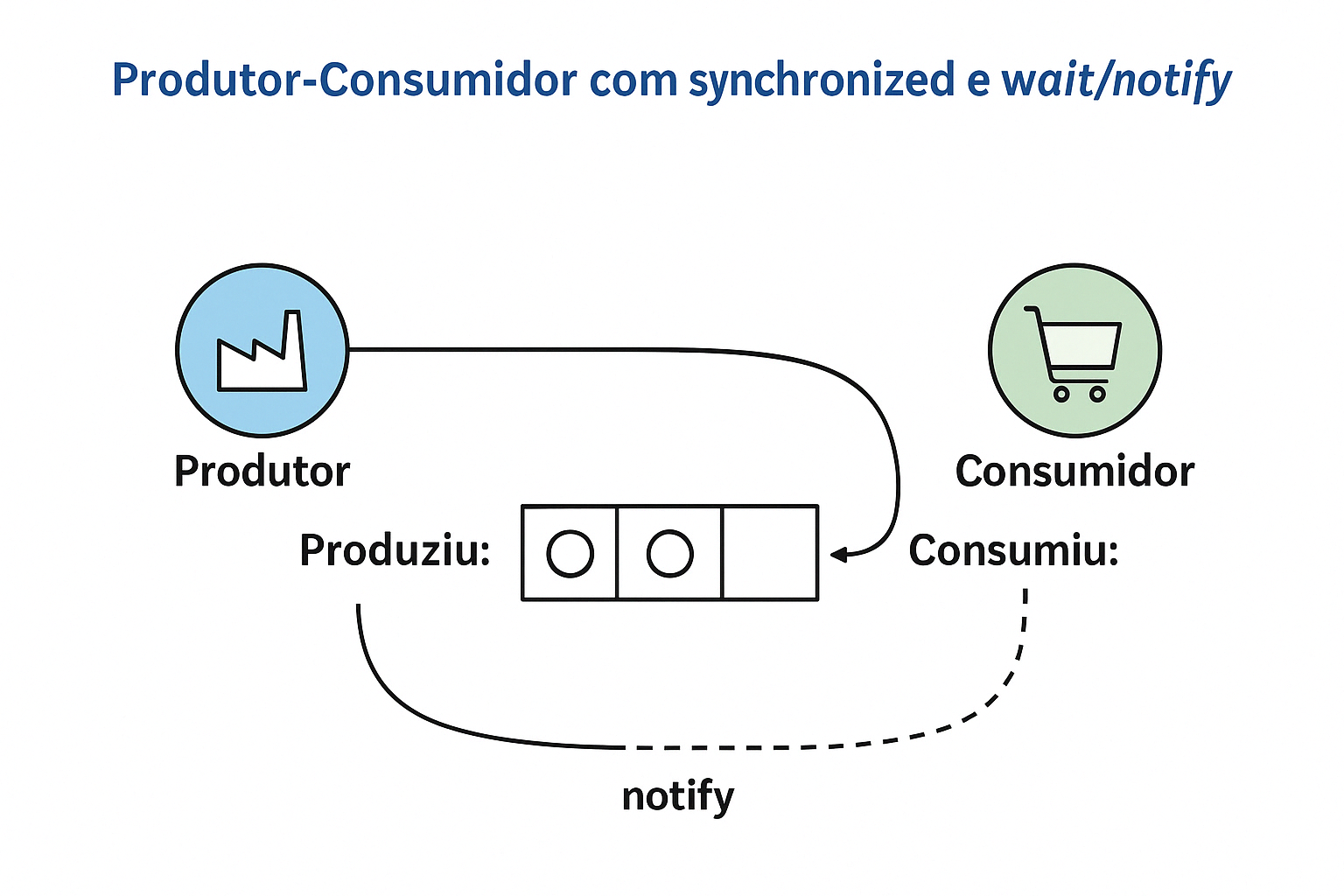
Exemplo em Java – Produtor-Consumidor com Monitor (synchronized + wait/notify)
Este exemplo utiliza os recursos nativos da linguagem Java para implementar uma solução ao problema clássico do produtor-consumidor, empregando um monitor com os métodos synchronized, wait() e notifyAll().
class MonitorBuffer {
private int[] buffer;
private int count = 0;
public MonitorBuffer(int size) {
buffer = new int[size];
}
public synchronized void produce(int item) throws InterruptedException {
while (count == buffer.length) // Buffer cheio
wait(); // Dorme
buffer[count++] = item;
System.out.println("Produziu: " + item);
notifyAll(); // Acorda consumidores
}
public synchronized int consume() throws InterruptedException {
while (count == 0) // Buffer vazio
wait(); // Dorme
int item = buffer[--count];
System.out.println("Consumiu: " + item);
notifyAll(); // Acorda produtores
return item;
}
}
Explicação detalhada:
- A classe
MonitorBufferrepresenta um buffer limitado, compartilhado entre produtores e consumidores. - A variável
countindica quantos itens há atualmente no buffer. - O método
synchronizedgarante exclusão mútua: apenas uma thread executaproduce()ouconsume()por vez.
Método produce(int item)
- Se o buffer estiver cheio (
count == buffer.length), a thread produtora entra em espera comwait(). - Assim que houver espaço, a thread é acordada e pode inserir o item no buffer.
- Após inserir, o método chama
notifyAll()para acordar as threads consumidoras que estejam esperando por itens.
Método consume()
- Se o buffer estiver vazio (
count == 0), a thread consumidora entra em espera comwait(). - Quando um item for produzido, a thread é acordada e pode consumir (remover) um item do buffer.
- Após consumir, o método chama
notifyAll()para acordar os produtores que estejam esperando espaço no buffer.
Vantagens da abordagem:
- Utiliza os mecanismos de sincronização embutidos da linguagem Java, evitando a necessidade de semáforos externos.
- Fácil de implementar com os blocos
synchronizede os métodoswait()/notifyAll(). - Evita condição de corrida e deadlocks se bem utilizado.
Resumo: Este monitor Java garante a sincronização entre produtores e consumidores de forma segura e eficiente, controlando o acesso ao buffer e coordenando as esperas e notificações usando recursos nativos da linguagem.
Exemplo em C com PThreads – Produtor e Consumidor com Variáveis de Condição
Este exemplo implementa uma versão simplificada do problema Produtor-Consumidor utilizando pthread_mutex_t para exclusão mútua e pthread_cond_t para sincronização entre as threads.
#include <pthread.h>
#include <stdio.h>
#define BUFFER_SIZE 2
int buffer[BUFFER_SIZE];
int count = 0;
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t cond_full = PTHREAD_COND_INITIALIZER;
pthread_cond_t cond_empty = PTHREAD_COND_INITIALIZER;
void produce(int item) {
pthread_mutex_lock(&mutex);
while (count == BUFFER_SIZE)
pthread_cond_wait(&cond_full, &mutex); // Dorme se cheio
buffer[count++] = item;
printf("Produziu: %d\\n", item);
pthread_cond_signal(&cond_empty); // Acorda consumidor
pthread_mutex_unlock(&mutex);
}
void* consume(void* arg) {
pthread_mutex_lock(&mutex);
while (count == 0)
pthread_cond_wait(&cond_empty, &mutex); // Dorme se vazio
int item = buffer[--count];
printf("Consumiu: %d\\n", item);
pthread_cond_signal(&cond_full); // Acorda produtor
pthread_mutex_unlock(&mutex);
return NULL;
}
int main() {
pthread_t cons;
pthread_create(&cons, NULL, consume, NULL);
produce(42);
pthread_join(cons, NULL);
return 0;
}
Explicação detalhada:
- Buffer: Um array de inteiros com capacidade definida por
BUFFER_SIZE. A variávelcountcontrola quantos itens há no buffer no momento. - Mutex (
pthread_mutex_t): Garante que apenas uma thread (produtor ou consumidor) possa acessar o buffer por vez, evitando condições de corrida. - Variáveis de condição:
cond_full: sinaliza quando o buffer deixou de estar cheio (usada pelo consumidor para acordar o produtor).cond_empty: sinaliza quando o buffer deixou de estar vazio (usada pelo produtor para acordar o consumidor).
Função produce(int item):
- Tenta inserir um item no buffer.
- Se o buffer estiver cheio (
count == BUFFER_SIZE), o produtor dorme (bloqueia) compthread_cond_waitaté ser acordado por um consumidor. - Quando há espaço, insere o item, imprime uma mensagem e acorda um consumidor usando
pthread_cond_signal(&cond_empty).
Função consume(void* arg):
- Tenta remover um item do buffer.
- Se o buffer estiver vazio (
count == 0), a thread consumidora dorme compthread_cond_waitaté o produtor inserir algo. - Quando há itens disponíveis, consome um item, imprime uma mensagem e acorda o produtor com
pthread_cond_signal(&cond_full).
Função main():
- Cria uma thread consumidora e depois chama a função
produce(42)no thread principal. - O item
42é produzido e consumido com a devida sincronização.
Resumo:
Este exemplo demonstra o uso das primitivas de sincronização POSIX para coordenar duas threads que compartilham um recurso. O uso correto de mutex garante exclusão mútua, enquanto as variáveis de condição permitem que as threads esperem de forma eficiente por mudanças no estado do buffer.
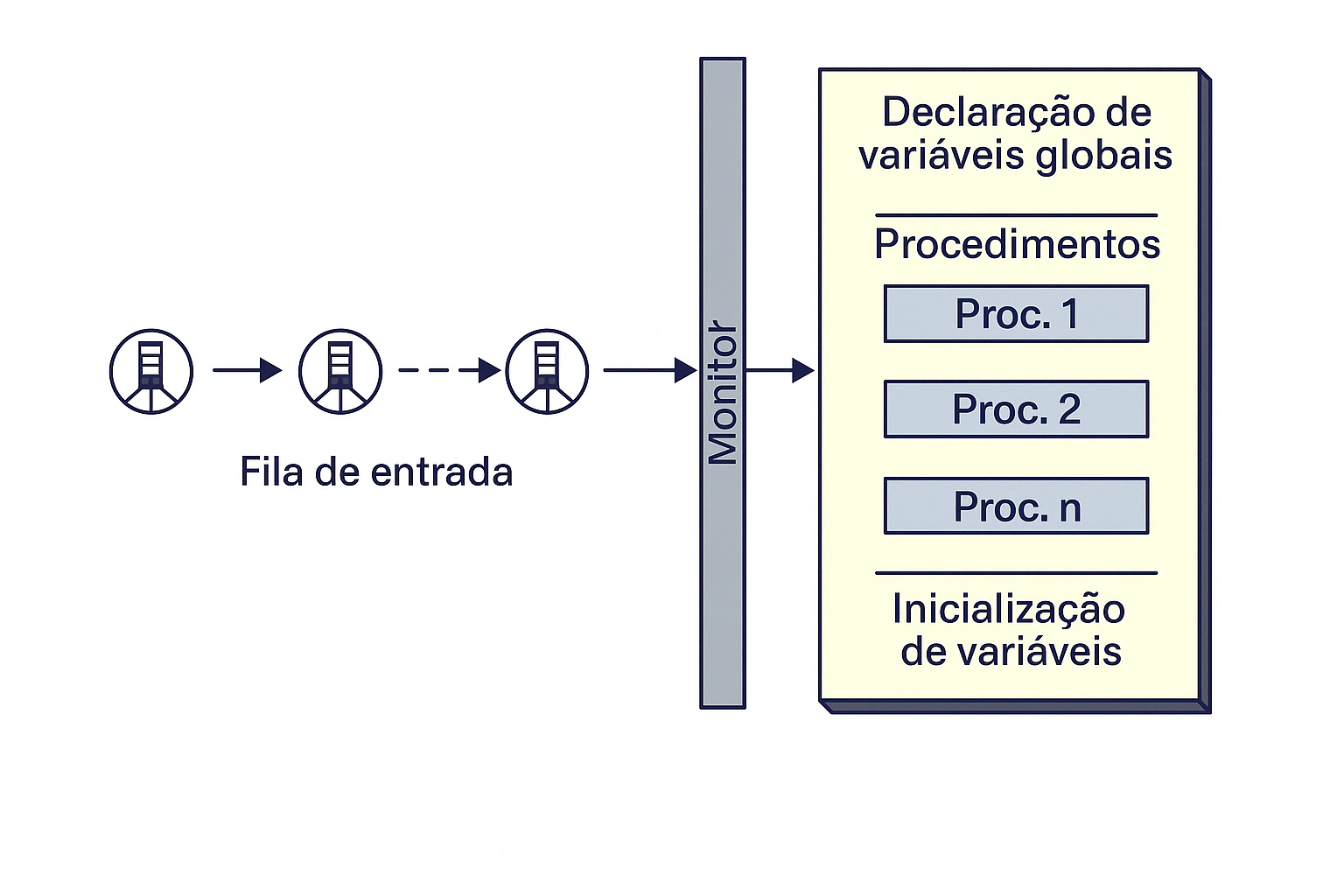
Monitores – Controle de Concorrência
A figura acima representa o funcionamento de um monitor, um mecanismo de sincronização de alto nível usado para controlar o acesso concorrente a recursos compartilhados por múltiplos processos ou threads.
Elementos da estrutura:
- Fila de entrada: Mostra os processos aguardando para entrar no monitor. Apenas um processo pode acessar o monitor por vez. Os demais ficam bloqueados nesta fila até que o recurso seja liberado.
- Monitor: É a estrutura que encapsula:
- Declaração de variáveis globais: Usadas internamente por todos os procedimentos do monitor.
- Procedimentos (Proc. 1, Proc. 2, ..., Proc. n): Representam as funções ou operações que acessam os dados protegidos. São executadas com exclusão mútua.
- Inicialização de variáveis: Parte executada uma única vez, geralmente no momento da criação do monitor.
Funcionamento:
O monitor garante que apenas um processo por vez execute um de seus procedimentos. Quando um processo entra, os outros ficam bloqueados na fila de entrada. Isso garante a exclusão mútua de forma automática.
Além disso, monitores frequentemente oferecem suporte a condições (como wait() e signal()) que permitem que processos sejam suspensos internamente e acordados por outros, sem liberar o monitor externamente.
Resumo:
O monitor combina estrutura de dados, sincronização e exclusão mútua em uma única abstração, sendo muito útil para resolver problemas como produtor-consumidor, leitores-escritores e buffers circulares de forma segura e modular.
Troca de Mensagens
OpenMP & Barriers
OpenMP: API para programação paralela em C/C++ e Fortran, baseada em diretivas que simplificam o uso de threads em arquiteturas de memória compartilhada (Tanenbaum, 2.3.9).
Barreiras: Pontos de sincronização onde todas as threads devem chegar antes de prosseguir. A diretiva #pragma omp barrier força essa espera explícita.
Vantagens: Coordena tarefas paralelas (ex.: cálculos em fases).
Limitações: Pode reduzir desempenho se as threads chegarem em tempos muito diferentes.
Exemplo em C: Threads calculam valores em duas fases, sincronizadas por uma barreira.
Barreira: garante que todas as threads alcancem um ponto antes de qualquer uma continuar.
Exemplo: processamento em etapas, onde todos precisam terminar uma fase antes da próxima.
#include omp.h
#include stdio.h
int main() {
int n = 4, a[4], b[4];
// Fase 1: Calcula quadrados em paralelo
#pragma omp parallel num_threads(4)
{
int tid = omp_get_thread_num();
if (tid < n) { // Cada thread processa um índice
a[tid] = tid * tid;
printf("Fase 1 - Thread %d calculou a[%d] = %d\\n", tid, tid, a[tid]);
}
// Barreira explícita: todas as threads esperam aqui
#pragma omp barrier
// Fase 2: Calcula cubos, dependendo dos resultados da Fase 1
if (tid < n) {
b[tid] = a[tid] * tid;
printf("Fase 2 - Thread %d calculou b[%d] = %d\\n", tid, tid, b[tid]);
}
}
// Imprime resultados finais
printf("Resultados finais:\\n");
for (int i = 0; i < n; i++) {
printf("a[%d] = %d, b[%d] = %d\\n", i, a[i], i, b[i]);
}
return 0;
}
Compilação: gcc -fopenmp exemplo.c -o exemplo
Resultado: Threads calculam a[i] (quadrados), esperam na barreira, depois calculam b[i] (cubos).

Código mais pesado:
#include <stdio.h>
#include <omp.h>
#include <unistd.h>
int main() {
printf("PID: %d\n", getpid());
#pragma omp parallel num_threads(4)
{
int id = omp_get_thread_num();
// Loop pesado para manter CPU ocupada
for (long i = 0; i < 10000000; i++);
printf("Thread %d terminou\n", id);
sleep(1); // tempo para observar no top
}
return 0;
}
Como observar as threads no Linux
# Compile gcc -fopenmp programa.c -o programa # Execute ./programa # Em outro terminal: ps -T -p PID top -H -p PID ls /proc/PID/task/
O que observar:
- Mesmo PID para todas as threads
- Cada thread com TID diferente
- Uso de CPU distribuído entre threads
Importante: OpenMP cria threads reais do sistema (modelo 1:1), visíveis diretamente pelo kernel Linux.
export OMP_NUM_THREADS=8 ./programa
Material EXTRA sobre OpenMP:
https://docs.ufpr.br/~jefer/professor/disciplinas/slides/dee354-openmp.html
Barreiras e RCU
Contexto: Em sistemas operacionais multiprocessados, é comum que múltiplas threads compartilhem dados. Para evitar inconsistências, utilizam-se mecanismos de sincronização, como barreiras e técnicas como o RCU, que otimizam o desempenho especialmente em cenários de leitura intensiva.
Barreiras: Mecanismo de sincronização onde todas as threads ou processos devem alcançar um ponto comum antes de qualquer um deles continuar. Isso garante que todos chegaram a uma etapa específica da execução (Tanenbaum, 2.3.9).
RCU (Read-Copy-Update): Técnica eficiente para permitir leituras simultâneas sem travas (lock-free reads), ideal para sistemas com muitos leitores (Tanenbaum, 2.3.10). Muito usada no kernel do Linux, ela separa as operações de leitura e escrita:
- Leitores acessam os dados diretamente, sem bloqueio.
- Escritores fazem uma cópia dos dados, atualizam a cópia e, após sincronização, substituem o ponteiro global.
RCU (Read-Copy-Update): permite múltiplos leitores simultâneos sem bloqueio, sendo muito utilizado no kernel Linux para alto desempenho.
Analogia: Imagine leitores lendo uma versão do jornal, enquanto o editor prepara uma nova edição. Quando estiver pronta, o editor apenas troca o jornal na banca — sem interromper os leitores anteriores.
Exemplo: Em um banco de dados com múltiplos leitores, as atualizações ocorrem copiando os dados, modificando a cópia e depois atualizando o ponteiro global.Exemplo prático (pseudo-C):
/* Lado do leitor */
rcu_read_lock(); // Início da sessão de leitura protegida
data = rcu_dereference(global_data); // Acessa ponteiro seguro
use(data); // Utiliza os dados lidos
rcu_read_unlock(); // Finaliza sessão de leitura
/* Lado do atualizador */
new_data = copy_of(global_data); // Copia estrutura atual
modify(new_data); // Aplica alterações na cópia
synchronize_rcu(); // Aguarda fim de leitores ativos
rcu_assign_pointer(global_data, new_data); // Atualiza ponteiro global com segurança
Explicação do código:
rcu_read_lock()ercu_read_unlock(): delimitam a seção crítica para leitura.rcu_dereference(): lê o ponteiro global com garantias de visibilidade de memória.copy_of(): gera uma cópia segura dos dados compartilhados.modify(): aplica as modificações desejadas na nova versão.synchronize_rcu(): bloqueia até que todos os leitores anteriores saiam de sua seção crítica.rcu_assign_pointer(): publica a nova versão para os leitores futuros.
Vantagens do RCU:
- Alta escalabilidade com múltiplos leitores simultâneos;
- Sem necessidade de bloqueio em leitura;
- Ideal para estruturas que raramente mudam, mas são frequentemente acessadas.
Diagrama explicativo:
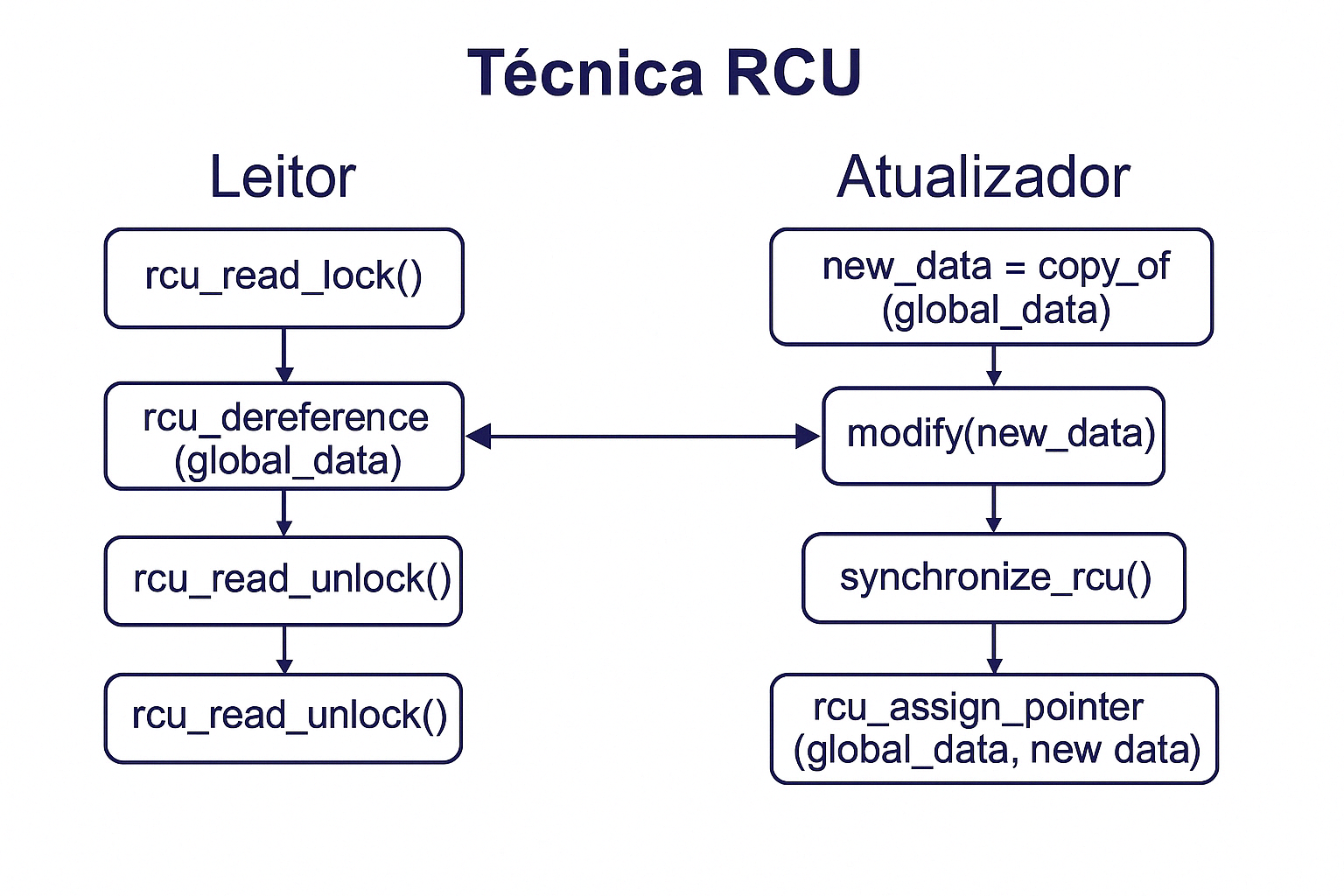
Fonte: Adaptado de Tanenbaum, Cap. 2.3.9 e 2.3.10
Simulação RCU – Read-Copy-Update
Prática de Sincronização
Objetivo: Explorar mecanismos de sincronização no terminal e em C, aplicando conceitos como pipes, sinais e semáforos (Silberschatz, Cap. 5).
Passo a Passo no Terminal:
- Visualizar processos:
ps -aux | grep firefox– Lista processos do Firefox com detalhes (PID, uso de CPU, etc.). - Usar pipes:
echo "Teste prático" | tr '[:lower:]' '[:upper:]' | wc -c– Converte para maiúsculas e conta caracteres (saída: 14). - Controlar execução:
sleep 10 &– Executa em background (anote o PID, ex.: [1] 1234).kill -SIGSTOP 1234– Pausa o processo.kill -SIGCONT 1234– Retoma a execução.
- Monitorar:
top -p $(pidof sleep)– Observa o processo em tempo real.
Exemplo em C – Produtor-Consumidor com Semáforos:
#include pthread.h
#include semaphore.h
#include stdio.h
#include unistd.h
#define BUFFER_SIZE 3
#define NUM_ITEMS 5
int buffer[BUFFER_SIZE];
int in = 0, out = 0; // Índices de inserção e remoção
sem_t empty, full, mutex;
void* produtor(void* arg) {
int id = *(int*)arg;
for (int i = 0; i < NUM_ITEMS; i++) {
sem_wait(&empty); // Espera vaga
sem_wait(&mutex); // Protege o buffer
buffer[in] = i;
printf("Produtor %d adicionou %d na posição %d\\n", id, i, in);
in = (in + 1) % BUFFER_SIZE;
sem_post(&mutex);
sem_post(&full); // Sinaliza item
sleep(1);
}
return NULL;
}
void* consumidor(void* arg) {
int id = *(int*)arg;
for (int i = 0; i < NUM_ITEMS; i++) {
sem_wait(&full); // Espera item
sem_wait(&mutex); // Protege o buffer
int item = buffer[out];
printf("Consumidor %d removeu %d da posição %d\\n", id, item, out);
out = (out + 1) % BUFFER_SIZE;
sem_post(&mutex);
sem_post(&empty); // Sinaliza vaga
sleep(2);
}
return NULL;
}
int main() {
sem_init(&empty, 0, BUFFER_SIZE); // Vagas iniciais
sem_init(&full, 0, 0); // Itens iniciais
sem_init(&mutex, 0, 1); // Mutex
pthread_t prod1, prod2, cons1;
int id1 = 1, id2 = 2, id3 = 1;
pthread_create(&prod1, NULL, produtor, &id1);
pthread_create(&prod2, NULL, produtor, &id2);
pthread_create(&cons1, NULL, consumidor, &id3);
pthread_join(prod1, NULL);
pthread_join(prod2, NULL);
pthread_join(cons1, NULL);
sem_destroy(&empty);
sem_destroy(&full);
sem_destroy(&mutex);
return 0;
}
Compilação: gcc -pthread exemplo.c -o exemplo
Saída esperada: Dois produtores enchem o buffer circular de tamanho 3, enquanto um consumidor o esvazia mais lentamente.

Dica de Experimento
- Execute múltiplas threads acessando a mesma variável
- Observe inconsistências sem mutex
- Adicione mutex e compare o resultado
Mini-Quiz
Bibliografia