
Gerenciamento de Memória

Introdução
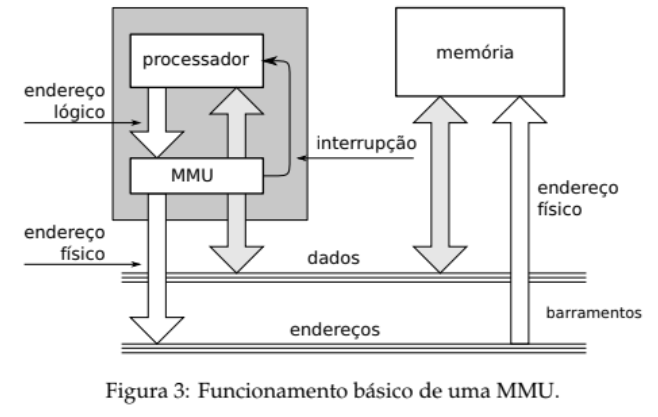
Endereços Lógicos e Físicos
Hierarquia:
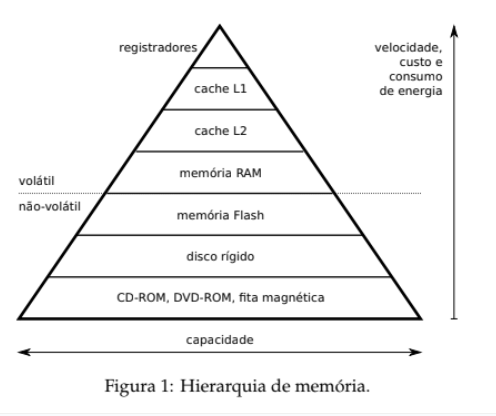
Conceitos Básicos
Endereço Lógico: Gerado pelo processador durante a execução de um programa; reflete a visão do programa.
Endereço Físico: Local real na memória RAM, definido após a tradução pela MMU.
MMU (Memory Management Unit): Hardware responsável por converter endereços lógicos em físicos, usando registradores de relocação.
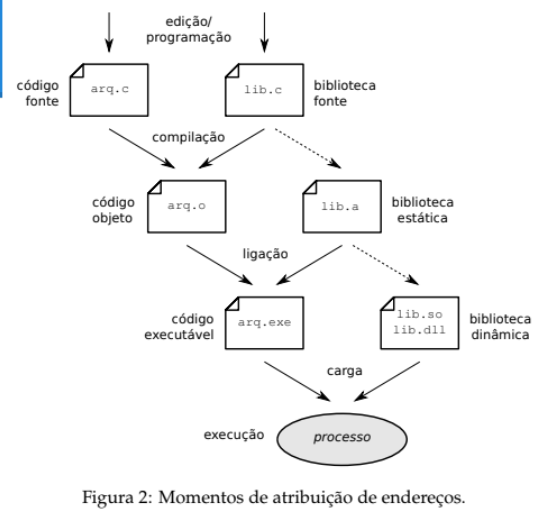
Modelo de Memória dos Processos
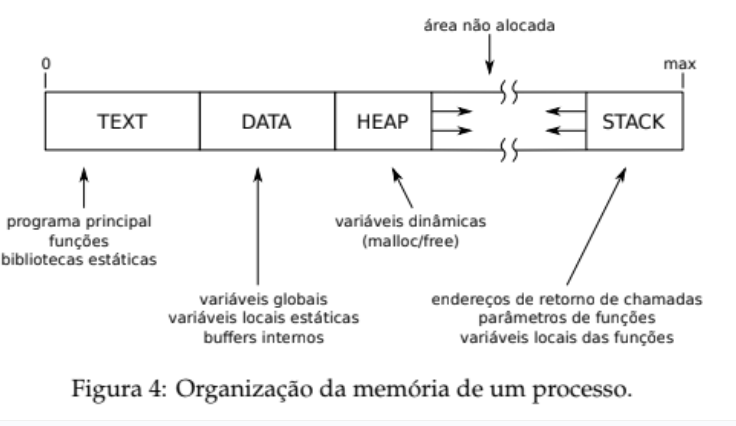
Estrutura Típica
- TEXT: Código executável – fixo, somente leitura. contém o código a ser executado pelo processo, gerado durante a compilação e a ligação com as bibliotecas. Esta área tem tamanho fixo, calculado durante a compilação, e normalmente só deve estar acessível para leitura e execução.
- DATA: Variáveis globais e estáticas – leitura e escrita. Esta área contém os dados estáticos usados pelo programa, ou seja, suas variáveis globais e as variáveis locais estáticas. Como o tamanho dessas variáveis pode ser determinado durante a compilação, esta área tem tamanho fixo; deve estar acessível para leituras e escritas, mas não para execução.
- HEAP: Memória alocada dinamicamente – tamanho variável, suscetível a fragmentação. Área usada para armazenar dados através de alocação dinâmica, usando operadores como malloc e free ou similares. Esta área tem tamanho variável, podendo aumentar/diminuir conforme as alocações/liberações de memória feitas pelo processo. Ao longo do uso, esta área pode se tornar fragmentada, ou seja, pode conter lacunas entre os blocos de memória alocados. São necessários então algoritmos de alocação que minimizem sua fragmentação.
- STACK: Pilha de execução – usada para chamadas de função e variáveis locais. Área usada para manter a pilha de execução do processo, ou seja, a estrutura responsável por gerenciar o fluxo de execução nas chamadas de função e também para armazenar os parâmetros, variáveis locais e o valor de retorno das funções. Geralmente a pilha cresce “para baixo”, ou seja, inicia em endereços elevados e cresce em direção aos endereços menores da memória. No caso de programas com múltiplas threads, esta área contém somente a pilha do programa principal. Como threads podem ser criadas e destruídas dinamicamente, a pilha de cada thread é mantida em uma área própria, geralmente alocada no heap.
Esquemas de Gerenciamento
Partições Fixas
Conceito
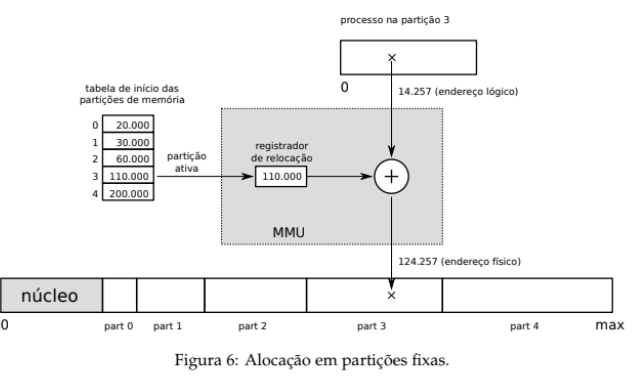
A técnica de partições fixas consiste em dividir a memória RAM em blocos de tamanho fixo, chamados de partições. Cada processo é carregado em uma dessas partições, e não pode usar mais memória do que a capacidade da partição que lhe foi atribuída.
Exemplo: Suponha que um processo queira acessar o endereço lógico 14.257. Ele está carregado na partição 3, cujo endereço inicial na memória física é 110.000. O hardware (MMU) soma esses valores:
Endereço físico = endereço base + endereço lógico = 110.000 + 14.257 = 124.257.
Esse é o endereço real que será acessado na RAM.
Vantagem: É uma técnica simples de implementar, pois não exige estruturas complexas de gerenciamento.
Desvantagem: Pode causar fragmentação interna — ou seja, sobras de memória dentro da partição que não são utilizadas, desperdiçando espaço.
Alocação por Segmentos
Conceito
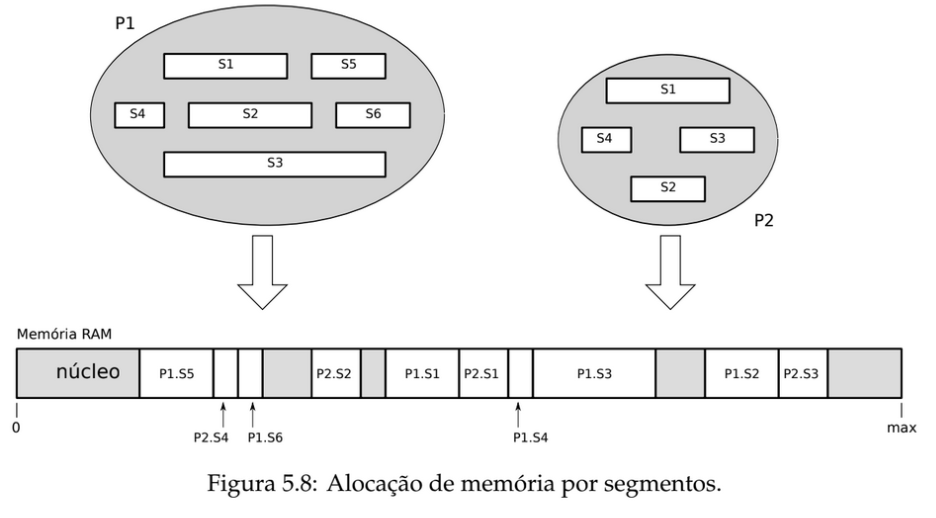
Na segmentação, a memória é organizada de forma lógica, refletindo a estrutura dos programas. Em vez de dividir a memória em blocos fixos (como na paginação), ela é separada em segmentos, como:
- código (instruções do programa)
- dados (variáveis globais, vetores, buffers)
- pilha (funções, chamadas recursivas, parâmetros)
Cada segmento possui dois parâmetros:
- Base: endereço inicial do segmento na memória física
- Limite: tamanho máximo do segmento
O processador utiliza essas informações para verificar se o acesso está dentro dos limites válidos.
Vantagem: Maior flexibilidade e permite compartilhamento de código entre processos, como bibliotecas.
Desvantagem: Pode causar fragmentação externa, já que os segmentos têm tamanhos diferentes e são alocados dinamicamente.
🧮Exemplo de Cálculo
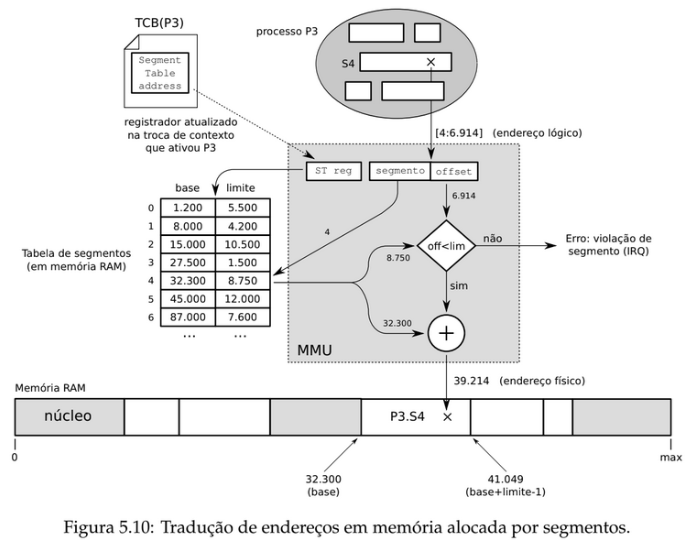
- Segmento requisitado:
2 - Offset dentro do segmento:
300 - Tabela de Segmentos: Segmento 2 tem base
5.000e limite1.000 - Verificação:
300 < 1.000→ Acesso válido - Endereço físico =
5.000 + 300 = 5.300
Exemplos de processadores que utilizam a alocação por segmentos incluem o 80.386 e seus sucessores (486, Pentium, Athlon e processadores correlatos).
Alocação Paginada
Conceito
No modelo de alocação paginada, tanto o espaço de endereços lógicos (gerado pelo processo) quanto a memória física (RAM) são divididos em blocos de tamanho fixo:
- Páginas: blocos do endereço lógico (geralmente de 4 KB = 4.096 bytes)
- Quadros (frames): blocos equivalentes na memória física
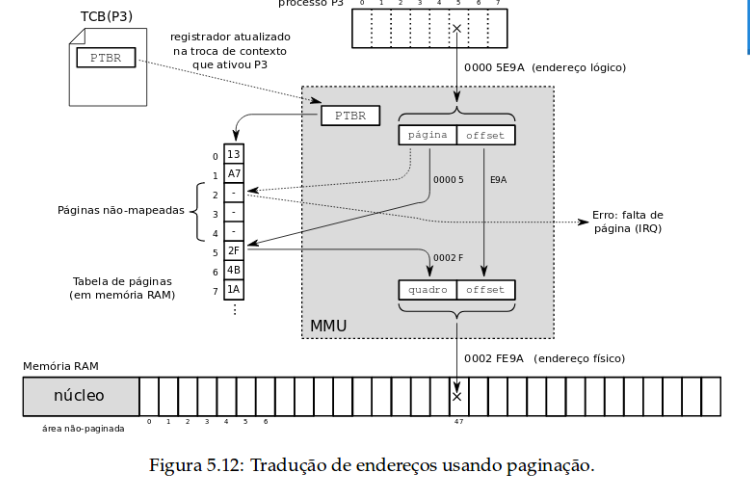
O mapeamento entre as páginas de um processo e os quadros disponíveis na memória física é feito por meio de uma tabela de páginas, que fica associada a cada processo. O processador localiza essa tabela usando o registrador chamado PTBR (Page Table Base Register).
Vantagens: evita a fragmentação externa e simplifica a alocação da memória.
Exemplo de Cálculo
- Endereço lógico: 20.000
- Tamanho da página: 4.096 bytes
- Divisão: 20.000 ÷ 4.096 → Página
4, comresto 784(offset) - Tabela de páginas: Página 4 mapeada para o Quadro 7
- Endereço físico:
(7 × 4.096) + 784 = 28.656

A divisão do espaço de endereçamento lógico de um processo em páginas pode ser feita de forma muito simples: como as páginas sempre têm 2n bytes de tamanho (por exemplo, 212 bytes para páginas de 4 KBytes) os n bits menos significativos de cada endereço lógico definem a posição daquele endereço dentro da página (deslocamento ou offset), enquanto os bits restantes (mais significativos) são usados para definir o número da página. Por exemplo, o processador Intel 80.386 usa endereços lógicos de 32 bits e páginas com 4 KBytes; um endereço lógico de 32 bits é decomposto em um offset de 12 bits, que representa uma posição entre 0 e 4.095 dentro da página, e um número de página com 20 bits. Dessa forma, podem ser endereçadas 220 páginas com 212 bytes cada (1.048.576 páginas com 4.096 bytes cada).
🔍Como a MMU traduz um endereço lógico
Como as páginas têm tamanho fixo (geralmente uma potência de 2, como 2¹² = 4.096), a divisão do endereço lógico é simples:
- Bits menos significativos: representam o offset (posição dentro da página)
- Bits mais significativos: representam o número da página
Por exemplo, com endereços lógicos de 32 bits:
- 12 bits para o offset (0 a 4.095)
- 20 bits para o número da página (total de 1.048.576 páginas)

 🧭
🧭 Etapas da tradução (resumo)
- Separar o endereço lógico em número da página e offset
- Buscar o número da página na tabela de páginas → obter número do quadro
- Construir o endereço físico:
quadro × tamanho da página + offset - Se a página não estiver carregada, ocorre um page fault
- O sistema operacional carrega a página da memória secundária (swap/disco)
Tradução de Endereços com a MMU
Memória Virtual e Swapping
O que é Memória Virtual?
A memória virtual é uma técnica que permite que processos utilizem mais memória do que a fisicamente disponível no sistema. Ela divide a memória em páginas e transfere páginas não utilizadas para o disco (swap), liberando espaço na memória RAM.
Algoritmos de Substituição de Páginas
- FIFO (First-In, First-Out): Substitui a página que está na memória há mais tempo.
- LRU (Least Recently Used): Substitui a página que não foi usada há mais tempo.
- NRU (Not Recently Used): Substitui uma página que não foi referenciada recentemente. (NRU precisa de informações do hardware (baseado em bits de controle mantidos pelo hardware: Bit R (Referenciado): indica se a página foi acessada recentemente. Bit M (Modificado): indica se a página foi escrita (alterada).), que mudam dinamicamente conforme os acessos. Como não temos acesso a esses bits em um exemplo estático, só podemos estimar seu comportamento.)
- Ótimo: Substitui a página que será usada no futuro mais distante (ideal, mas não implementável na prática).
Funcionamento da Memória Virtual
A memória virtual é uma técnica que permite que os processos usem mais memória do que a quantidade física instalada (RAM). Para isso, o sistema operacional armazena temporariamente páginas de memória em um espaço no disco, chamado swap.
Quando um processo acessa uma página que não está na RAM, ocorre uma falta de página (page fault). Nesse momento:
- O sistema operacional localiza a página no disco (área de swap).
- Se houver espaço na RAM, ela é carregada diretamente.
- Se não houver espaço, o sistema escolhe uma página existente para remover (usando um algoritmo de substituição).
- A nova página é então carregada na RAM, e a execução do processo continua.
Esse processo é transparente para o programa, mas afeta diretamente o desempenho — quanto mais page faults, maior o tempo de espera.
🧮Exemplo de Cálculo de Page Faults (FIFO)
Considere um sistema com 3 frames disponíveis na RAM e a seguinte sequência de referências a páginas:
1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5Utilizando o algoritmo FIFO (First-In, First-Out), temos:
- Página 1 → Page Fault (Frames: [1])
- Página 2 → Page Fault (Frames: [1, 2])
- Página 3 → Page Fault (Frames: [1, 2, 3])
- Página 4 → Page Fault (remove 1) → (Frames: [4, 2, 3])
- Página 1 → Page Fault (remove 2) → (Frames: [4, 1, 3])
- Página 2 → Page Fault (remove 3) → (Frames: [4, 1, 2])
- Página 5 → Page Fault (remove 4) → (Frames: [5, 1, 2])
- Página 1 → Já na memória (Frames: [5, 1, 2])
- Página 2 → Já na memória (Frames: [5, 1, 2])
- Página 3 → Page Fault (remove 5) → (Frames: [3, 1, 2])
- Página 4 → Page Fault (remove 1) → (Frames: [3, 4, 2])
- Página 5 → Page Fault (remove 2) → (Frames: [3, 4, 5])
Total de Page Faults: 9
🔁
Exemplo de Cálculo de Page Faults (LRU)
O algoritmo LRU (Least Recently Used) substitui a página que está na memória há mais tempo sem ser usada. Ele tenta prever que páginas não serão utilizadas em breve, com base no uso passado.
Vamos usar a mesma sequência de referências e 3 frames na RAM:
1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5Acompanhe a execução passo a passo:
- Página 1 → Page Fault (Frames: [1])
- Página 2 → Page Fault (Frames: [1, 2])
- Página 3 → Page Fault (Frames: [1, 2, 3])
- Página 4 → Page Fault → Remove 1 (menos recentemente usada) → (Frames: [4, 2, 3])
- Página 1 → Page Fault → Remove 2 → (Frames: [4, 1, 3])
- Página 2 → Page Fault → Remove 3 → (Frames: [4, 1, 2])
- Página 5 → Page Fault → Remove 4 → (Frames: [5, 1, 2])
- Página 1 → Já na memória → (Frames: [5, 1, 2])
- Página 2 → Já na memória → (Frames: [5, 1, 2])
- Página 3 → Page Fault → Remove 5 → (Frames: [3, 1, 2])
- Página 4 → Page Fault → Remove 1 → (Frames: [3, 4, 2])
- Página 5 → Page Fault → Remove 2 → (Frames: [3, 4, 5])
Total de Page Faults: 10
Comparativo de Algoritmos de Substituição de Páginas
| Algoritmo | Descrição | Page Faults | Observações |
|---|---|---|---|
| FIFO | Remove a página que está na memória há mais tempo (ordem de chegada). | 9 | Simples, mas pode remover páginas ainda úteis. |
| LRU | Remove a página que não é usada há mais tempo. | 10 | Mais eficiente que FIFO, mas com maior custo de implementação. |
| NRU | Remove uma página que não foi referenciada recentemente, priorizando páginas não modificadas. | Varia (depende do clock) | Usa bits de referência e modificação; eficiente e comum em sistemas reais. |
| Ótimo | Remove a página que será usada mais tarde no futuro. | 7 | Melhor resultado teórico, mas não pode ser implementado na prática. |
Swapping
O swapping é o processo de mover páginas de memória RAM para o disco (swap space) e vice-versa. Ele é essencial para sistemas com memória física limitada, mas pode impactar o desempenho devido ao tempo de acesso ao disco.
Exemplo de Cálculo de Tempo de Swapping
Suponha que o tempo de acesso à RAM seja de 100 ns e o tempo de acesso ao disco seja de 10 ms (10.000.000 ns). Se ocorrer um page fault, o tempo total para acessar uma página será:
Tempo de acesso = Tempo de busca no disco + Tempo de carregamento na RAM
Tempo de acesso = 10 ms + 100 ns ≈ 10 ms
Figuras e Diagramas
Figura 1: Diagrama de memória virtual e swapping.

Figura 2: Funcionamento da memória virtual com páginas e frames.
Referências Adicionais
- Tanenbaum, A. S. - Sistemas Operacionais Modernos
- Silberschatz, A. - Fundamentos de Sistemas Operacionais
Algoritmos de Substituição de Páginas
O que são Algoritmos de Substituição?
Quando a memória RAM está cheia e ocorre um page fault, o sistema operacional precisa decidir qual página remover para liberar espaço. Os algoritmos de substituição determinam essa decisão, impactando diretamente o desempenho do sistema.
Principais Algoritmos
-
FIFO (First-In, First-Out):
Remove a página que está na memória há mais tempo.
Exemplo: Sequência de páginas: 1, 2, 3, 4, 1, 2, 5. Com 3 frames, os page faults ocorrem nas páginas 1, 2, 3, 4, 5. -
LRU (Least Recently Used):
Remove a página que não foi usada há mais tempo.
Exemplo: Sequência de páginas: 1, 2, 3, 4, 1, 2, 5. Com 3 frames, os page faults ocorrem nas páginas 1, 2, 3, 4, 5. - NRU (Not Recently Used): Remove uma página que não foi referenciada recentemente, priorizando páginas não modificadas.
- Ótimo: Remove a página que será usada no futuro mais distante. É teórico e não implementável na prática, mas serve como referência para comparação.
Exemplo Prático
Considere a seguinte sequência de referências a páginas: 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5.
Com 3 frames de memória, calcule o número de page faults para cada algoritmo:
- FIFO: 9 page faults.
- LRU: 8 page faults.
- Ótimo: 7 page faults.
Animação com p5.js (FIFO)
Abaixo está uma animação interativa que simula o funcionamento do algoritmo FIFO. Clique no botão para avançar as referências e observe como as páginas são substituídas.
Status: Aguardando início...
Figuras e Diagramas

Figura : Substituição de Página.
Segmentação com Paginação
Atividades
Estudo de Casos Práticos
Atividade Prática: Explorando o Gerenciamento de Memória no Linux
Nesta atividade, você vai explorar o gerenciamento de memória no Linux usando comandos de terminal. O objetivo é observar e analisar o uso de memória em um sistema real.
Passos da Atividade
-
Comando
free- Visão Geral da Memória- Execute
free -mno terminal. - Anote os valores para:
- Memória Total
- Memória Utilizada
- Memória Livre
- Memória Compartilhada
- Buffers/Cache
- Memória Disponível
- Swap
- Responda:
- O que significa cada coluna na saída do
free? - Qual a diferença entre "free" e "available" memory?
- O sistema está usando swap? Como você pode determinar isso?
- O que significa cada coluna na saída do
- Execute
-
Comando
topouhtop- Uso de Memória por Processo- Execute
topouhtop. - Ordene os processos por uso de memória (em
top:Shift+M, emhtop: clique no cabeçalhoMEM%). - Identifique os processos que consomem mais memória.
- Responda:
- O que as colunas
RESeVIRTrepresentam? - Por que um processo pode ter um
VIRTmuito maior queRES?
- O que as colunas
- Execute
-
Comando
ps- Informações Detalhadas de Processos- Execute
ps aux | less. - Localize as colunas
RSSeVSZ. - Compare a saída do
pscom a dotop. - Responda:
- O que
RSSeVSZrepresentam?
- O que
- Execute
-
Comando
pmap- Mapa de Memória de um Processo- Encontre o PID de um processo (ex: navegador) usando
topoups. - Execute
pmap <PID> | less. - Examine os segmentos de memória listados.
- Responda:
- O que cada tipo de segmento representa (ex:
[heap],[stack])? - Por que existem tantos segmentos de memória para um único processo?
- O que cada tipo de segmento representa (ex:
- Encontre o PID de um processo (ex: navegador) usando
-
Arquivo
/proc/meminfo- Informações Detalhadas do Sistema- Execute
cat /proc/meminfo | less. - Localize e anote os valores para:
MemTotalMemFreeMemAvailableSwapTotalSwapFreeCachedBuffers
- Responda:
- O que
CachedeBuffersrepresentam? - Por que o sistema operacional usa cache e buffers?
- O que
- Execute
Discussão e Conclusão
Reflita sobre como o sistema gerencia a memória e como diferentes programas afetam o uso de memória. Discuta a importância do gerenciamento de memória para o desempenho e a estabilidade do sistema.
Bibliografia
Exercícios e Discussão
Conclusão
Mini-Quiz